←
Quay lại
12/01/2026
•
38 phút
•
Chương 13: Từ ASCII tới Unicode

Mỗi khi ta vọc máy tính bảng hay lướt điện thoại, hoặc ngồi bên laptop hay máy tính bàn, ta luôn thấy chữ. Hết đọc tới gõ, rồi sao chép nội dung từ chỗ này để dán vào chỗ kia − từ trang web tới các trình soạn thảo, từ email tới mạng xã hội, từ những câu đùa vui trên mạng tới những người bạn mà ta "mess" tới.
Không gì kể trên có thể thành hiện thực nếu không có một quy chuẩn biểu diễn ký tự chữ bằng bit và byte trên máy tính. Và mã hoá ký tự, không có gì để bàn cãi, là tiêu chuẩn máy tính quan trọng nhất. Tính thiết yếu của nó cho khả năng giao tiếp hiện đại giúp vượt qua rào cản khác biệt của ứng dụng và các hệ điều hành khác nhau, giữa cấu trúc phần cứng và phần mềm, và thậm chí giữa biên giới các quốc gia.
Nhưng không phải lúc nào văn bản cũng được biểu diễn trơn tru. Vào đầu năm 2021, lúc tôi bắt đầu xem lại chương này thì có nhận được một email từ nhà cung cấp dịch vụ web-hosting (lưu trữ web) với tiêu đề:
We’ve received your payment, thanks.
Chắc hẳn bạn cũng đã từng một lần nhìn thấy những kí tự kì quặc, trông thật lạ lùng, nhưng tới cuối chương bạn sẽ biết đích xác tại sao những thứ này tồn tại.
Cuốn sách này bắt đầu với một thảo luận về 2 hệ thống đại diện văn bản bằng mã nhị phân. Mã Morse mới đầu có thể trông không giống mã nhị phân lắm bởi nó gồm các chấm và gạch và khoảng cách ở giữa với độ dài ngắn khác nhau. Nhưng hãy nhớ rằng mọi thứ trong mã Morse là bội số của độ dài một chấm: Một gạch dài gấp 3 lần một chấm, khoảng cách giữa các chữ cái dài bằng một gạch, khoảng cách giữa các chữ dài gấp đôi gạch. Nếu chấm là bit 1, thì gạch là 3 bit 1 liền kề, trong khi khoảng cách là chuỗi các bit 0. Dưới đây là "HI THERE" trong mã Morse với chữ số nhị phân tương ứng:
Không gì kể trên có thể thành hiện thực nếu không có một quy chuẩn biểu diễn ký tự chữ bằng bit và byte trên máy tính. Và mã hoá ký tự, không có gì để bàn cãi, là tiêu chuẩn máy tính quan trọng nhất. Tính thiết yếu của nó cho khả năng giao tiếp hiện đại giúp vượt qua rào cản khác biệt của ứng dụng và các hệ điều hành khác nhau, giữa cấu trúc phần cứng và phần mềm, và thậm chí giữa biên giới các quốc gia.
Nhưng không phải lúc nào văn bản cũng được biểu diễn trơn tru. Vào đầu năm 2021, lúc tôi bắt đầu xem lại chương này thì có nhận được một email từ nhà cung cấp dịch vụ web-hosting (lưu trữ web) với tiêu đề:
We’ve received your payment, thanks.
Chắc hẳn bạn cũng đã từng một lần nhìn thấy những kí tự kì quặc, trông thật lạ lùng, nhưng tới cuối chương bạn sẽ biết đích xác tại sao những thứ này tồn tại.
Cuốn sách này bắt đầu với một thảo luận về 2 hệ thống đại diện văn bản bằng mã nhị phân. Mã Morse mới đầu có thể trông không giống mã nhị phân lắm bởi nó gồm các chấm và gạch và khoảng cách ở giữa với độ dài ngắn khác nhau. Nhưng hãy nhớ rằng mọi thứ trong mã Morse là bội số của độ dài một chấm: Một gạch dài gấp 3 lần một chấm, khoảng cách giữa các chữ cái dài bằng một gạch, khoảng cách giữa các chữ dài gấp đôi gạch. Nếu chấm là bit 1, thì gạch là 3 bit 1 liền kề, trong khi khoảng cách là chuỗi các bit 0. Dưới đây là "HI THERE" trong mã Morse với chữ số nhị phân tương ứng:
. . . . . . ___ . . . . . . ___ . . 10101010001010000001110001010101000100010111010001000000
Mã Morse được phân vào nhóm mã có độ dài bit thay đổi bởi vì các kí tự khác nhau cần một số lượng bit khác nhau.
Theo lối này thì Braille đơn giản hơn. Mỗi kí tự được đại diện bởi một mảng 6 chấm và mỗi chấm có thể nổi hoặc không. Braille rõ ràng là mã 6-bit, có nghĩa là mỗi kí tự có thể được biểu diễn bởi một giá trị 6 bit. Một lưu ý nhỏ là cần các kí tự Braille bổ sung để biểu diễn số và chữ viết hoa. Bạn có thể nhớ lại là số trong Braille cần một mã shift (chuyển) − một kí tự Braille thay đổi ý nghĩa các kí tự theo sau.
Mã shift cũng xuất hiện trong một mã nhị phân đời đầu khác, được phát minh trong mối liên hệ với điện báo in vào những năm 1870. Đây là công trình của Émile Baudot, một nhân viên của French Telegraph Service, và mã này vẫn còn được biết đến với tên của ông. Mã Baudot được dùng vào những năm 1960 − bởi Western Union, ví dụ, để gửi và nhận tin nhắn văn bản tên là telegram (điện tín). Ngay cả ngày nay, đôi khi bạn vẫn nghe những người làm máy tính từ thời kỳ đầu gọi tốc độ truyền dữ liệu nhị phân là tốc độ baud.
Mã Baudot thường được dùng trong máy điện báo chữ (teletypewriter, mình sẽ viết tắt thành TTY), một thiết bị có bàn phím trông khá giống máy đánh chữ, nhưng chỉ có 30 phím và một phím cách. Các phím hoạt động như những công tắc, sinh ra mã nhị phân rồi gửi nó đi qua dây xuất của máy TTY, từng bit nối tiếp nhau. TTY cũng bao gồm một cơ chế in. Mã đến qua dây đầu vào của TTY kích hoạt điện từ để in kí tự lên giấy.
Baudot là mã 5 bit, nên chỉ có 32 mã, nằm trong khoảng từ 00h tới 1Fh trong hex. Đây là cách 32 mã này chuyển thành chữ trong bảng chữ cái:
Mã Hex Chữ Baudot Mã Hex Chữ Baudot 00 10 E 01 T 11 Z 02 Carriage Return 12 D 03 O 13 B 04 Space 14 S 05 H 15 Y 06 N 16 F 07 M 17 X 08 Line Feed 18 A 09 L 19 W 0A R 1A J 0B G 1B Figure Shift 0C I 1C U 0D P 1D Q 0E C 1E K 0F V 1F Letter Shift
Mã 00h không được gán gì cả. Trong 31 mã còn lại, 26 mã được gán cho chữ cái, 5 mã còn lại được biểu thị bằng chữ in nghiêng trong bảng.
Mã 04h là mã Space (dấu cách), dùng để tạo khoảng trắng giữa các từ. Mã 02h và 08h lần lượt là Carriage Return (xuống dòng – trở về đầu dòng) và Line Feed (xuống dòng – đẩy giấy). Những thuật ngữ này bắt nguồn từ máy đánh chữ: khi bạn gõ trên máy đánh chữ và đến cuối dòng, bạn sẽ đẩy một cần gạt hoặc nhấn một nút để thực hiện hai việc. Đầu tiên, nó khiến cho bộ phận giữ giấy (carriage) dịch sang phải (hoặc cơ cấu in dịch sang trái) để dòng tiếp theo bắt đầu từ lề trái của tờ giấy. Đó chính là carriage return. Tiếp theo, máy đánh chữ cuộn giấy để dòng tiếp theo nằm ngay dưới dòng vừa gõ xong. Đó là line feed.
Trong mã Baudot, hai hành động này được biểu diễn bằng hai mã riêng biệt, và một máy in TTY dùng Baudot sẽ phản hồi theo các mã đó khi in.
Số và dấu câu trong hệ Baudot ở đâu? Đó là mục đích của mã 1Bh, trong bảng là Figure Shift. Tất cả mã sau Figure Shift được dịch thành số và dấu câu cho tới khi mã Letter Shift (1Fh) biến chúng trở lại thành chữ cái. Đây là mã cho số và dấu:
Mã Hex Baudot Figure Mã Hex Baudot Figure 00 10 3 01 5 11 + 02 Carriage Return 12 Who Are You? 03 9 13 ? 04 Space 14 ' 05 # 15 6 06 , 16 $ 07 . 17 / 08 Line Feed 18 - 09 ) 19 2 0A 4 1A Bell 0B & 1B Figure Shift 0C 8 1C 7 0D 0 1D 1 0E : 1E ( 0F = 1F Letter Shift
Bảng trên cho thấy cách các mã này được dùng ở Hoa Kỳ. Bên ngoài US, mã 05h, 0Bh và 16h thường được dùng cho các chữ cái có dấu trong ngôn ngữ châu Âu. Mã Bell dùng để rung chuông cho máy TTY. Mã "Who Are You?" bật cơ chế cho phép TTY tự xác minh.
Như mã Morse, Baudot không phân biệt giữa chữ thường và chữ hoa. Câu
I SPENT $25 TODAY.
được biểu diễn bằng chuỗi dữ liệu hex sau:
I S P E N T $ 2 5 T O D A Y . 0C 04 14 0D 10 06 01 04 1B 16 19 01 1F 04 01 03 12 18 15 1B 07 02 08
Chú ý 3 mã shift: 1Bh ngay trước dấu dollar, 1Fh sau số và lại 1Bh trước dấu chấm. Dòng kết thúc với mã cho carriage return và line feed.
Không may là nếu bạn gửi dòng dữ liệu này liên tiếp 2 lần tới một máy in TTY, nó sẽ in ra là:
I SPENT $25 TODAY. 8 '03,5 $25 TODAY.
Tại sao thế? Mã shift cuối cùng trước khi máy in nhận dòng thứ 2 là mã Figure Shift, nên mã đầu dòng 2 được dịch thành số cho tới khi gặp mã Letter Shift.
Vấn đề kiểu này là hệ quả khó chịu thường thấy với mã shift. Khi đến lúc phải thay thế Baudot với thứ hiện đại và đa dụng hơn, người ta muốn tránh được mã shift và định nghĩa mã riêng cho chữ hoa và chữ thường.
Vậy mã mới này cần bao nhiêu bit? Nếu bạn chỉ tập trung vào tiếng Anh và bắt đầu cộng dồn các kí tự, sẽ cần 52 mã cho chữ hoa và chữ thường trong bảng chữ cái Latin và 10 mã cho chữ số từ 0 tới 9. Bạn đã cần 62 mã rồi. Ném vào vài dấu câu sẽ được hơn 64, là giới hạn của 6 bit. Tuy nhiên vẫn còn chút dư địa trước khi vượt mốc 128 ký tự, lúc ấy mới phải dùng 8 bit.
Vậy câu trả lời là 7. Bạn cần 7 bit để đại diện tất cả kí tự thường xuất hiện trong văn bản tiếng Anh mà không cần mã shift.
Thứ thay thế mã Baudot nói trên là mã 7 bit tên American Standard Code for Information Interchange (Mã Trao Đổi Thông Tin Chuẩn Mỹ), viết tắt thành ASCII, đọc là 'aski. Nó được chuẩn hoá vào năm 1967 và vẫn là một trong những tiêu chuẩn quan trọng nhất trong toàn ngành máy tính. Với một ngoại lệ (mà tôi sẽ sớm mô tả), bất cứ khi nào bắt gặp văn bản máy tính, khá chắc là có liên quan chút đỉnh tới ASCII.
Như mã 7 bit, ASCII dùng mã nhị phân 0000000 tới 1111111, hay từ 00h tới 7Fh trong hex. Rồi bạn sẽ thấy hết 128 mã ASCII, nhưng trước tiên tôi muốn chia mã thành 4 nhóm, mỗi nhóm 32 mã rồi bỏ qua 32 mã đầu vì những mã này hơi khó hiểu so với những mã còn lại. Nhóm thứ 2 với 32 mã gồm dấu câu và 10 chữ số. Bảng này cho thấy mã hex từ 20h tới 3Fh và các kí tự tương ứng với chúng:
Mã Hex ASCII Mã Hex ASCII 20 Space 30 0 21 ! 31 1 22 ‟ 32 2 23 # 33 3 24 $ 34 4 25 % 35 5 26 & 36 6 27 ‛ 37 7 28 ( 38 8 29 ) 39 9 2A * 3A : 2B + 3B ; 2C , 3C < 2D - 3D = 2E . 3E > 2F / 3F ?
Để ý 20h là kí tự khoảng cách chia chữ và câu.
32 mã tiếp theo gồm chữ hoa và dấu câu khác. Ngoài dấu @ và gạch dưới, những dấu câu này thường không xuất hiện trong máy đánh chữ nhưng lại là chuẩn bàn phím máy tính.
Mã Hex ASCII Mã Hex ASCII 40 @ 50 P 41 A 51 Q 42 B 52 R 43 C 53 S 44 D 54 T 45 E 55 U 46 F 56 V 47 G 57 W 48 H 58 X 49 I 59 Y 4A J 5A Z 4B K 5B [ 4C L 5C \ 4D M 5D ] 4E N 5E ^ 4F O 5F _
32 kí tự tiếp theo gồm tất cả chữ thường và những dấu câu khác, và lần nữa chúng cũng ít được thấy trên máy đánh chữ nhưng là tiêu chuẩn bàn phím:
Mã Hex ASCII Mã Hex ASCII
60 ` 70 p
61 a 71 q
62 b 72 r
63 c 73 s
64 d 74 t
65 e 75 u
66 f 76 v
67 g 77 w
68 h 78 x
69 i 79 y
6A j 7A z
6B k 7B {
6C l 7C |
6D m 7D }
6E n 7E ~
6F o Để ý bảng này thiếu kí tự cuối cùng tương ứng với mã 7Fh. Bạn sẽ thấy nó sau.
Chuỗi văn bản
Hello, you!
có thể được biểu diễn trong ASCII bằng mã hex
H e l l o , y o u ! 48 65 6C 6C 6F 2C 20 79 6F 75 21
Chú ý dấu phẩy (mã 2Ch), dấu cách (mã 20h) và chấm than (mã 21h) cũng như các mã cho chữ cái. Đây là một câu ngắn khác:
I am 12 years old.
Và đại diện ASCII của nó là:
I a m 1 2 y e a r s o l d . 49 20 61 6D 20 31 32 20 79 65 61 72 73 20 6F 6C 64 2E
Để ý là số 12 trong câu này được biểu diễn bởi số hex 31h và 32h, là mã ASCII cho chữ số 1 và 2. Khi số 12 là một phần của dòng văn bản, nó không nên được biểu diễn bởi mã hex 01h và 02h, hay mã hex 0Ch. Những mã này mang nghĩa hoàn toàn khác trong ASCII.
Một chữ hoa nào đó trong ASCII khác với chữ thường một khoảng tương ứng 20h. Điều này giúp máy tính dễ dàng đổi giữa chữ hoa và thường: chỉ cần thêm 20h vào mã chữ hoa để đổi về chữ thường, và trừ 20h để đổi từ chữ thường thành hoa. (Nhưng thậm chí không cần phải cộng mà chỉ cần đổi một bit là được. Bạn sẽ gặp kĩ thuật này ở cuối sách.)
95 mã ASCII bạn vừa thấy được gọi là graphic characters (kí tự đồ hoạ) bởi vì chúng có biểu diễn trực quan. ASCII cũng gồm 33 control character (kí tự điều khiển) mà không có biểu diễn trực quan nhưng thay vào đó lại thực hiện những chức năng cụ thể. Cho đủ bộ, đây là 33 mã điều khiển ASCII nhưng đừng lo lằng nếu trông chúng khó hiểu. Vào lúc ASCII được phát triển, nó chủ yếu dùng cho TTY và nhiều mã này giờ đã bị lãng quên.
Mã Hex Viết tắt Tên kí tự điều khiển ASCII 00 NUL Null (không có gì) 01 SOH Start of Heading (Bắt đầu tiêu đề) 02 STX Start of Text (Bắt đầu văn bản) 03 ETX End of Text (Kết thúc văn bản) 04 EOT End of Transmission (Kết thúc đường truyền) 05 ENQ Enquiry (Câu hỏi) 06 ACK Acknowledge (Báo nhận) 07 BEL Bell (Chuông) 08 BS Backspace (Xoá) 09 HT Horizontal Tabulation (Tab ngang) 0A LF Line Feed 0B VT Vertical Tabulation (Tab dọc) 0C FF Form Feed 0D CR Carriage Return 0E SO Shift-Out 0F SI Shift-In 10 DLE Data Link Escape 11 DC1 Device Control 1 12 DC2 Device Control 2 13 DC3 Device Control 3 14 DC4 Device Control 4 15 NAK Negative Acknowledge 16 SYN Synchronous Idle 17 ETB End of Transmission Block 18 CAN Cancel 19 EM End of Medium 1A SUB Substitue Character 1B ESC Escape 1C FS File Separator or Information Separator 4 1D GS Group Separator or Information Separator 3 1E RS Record Separator or Information Separator 2 1F US Unit Separator or Information Separator 1 7F DEL Delete
Ý tưởng ở đây là kí tự điều khiển có thể được trộn lẫn với kí tự đồ hoạ để tạo thành các định dạng văn bản sơ đẳng. Dễ hiểu nhất là bạn hãy nghĩ về một thiết bị − như một máy TTY hoặc một máy in đơn giản − gõ các kí tự lên trang giấy tương ứng với dòng các mã ASCII. Đầu in của thiết bị thường phản ứng với mã kí tự bằng cách in một kí tự rồi dịch một khoảng về bên phải. Những kí tự điều khiển quan trọng nhất thay đổi hành vi này.
Ví dụ, xem chuỗi kí tự hex
410942094309
Kí tự 09 là mã Horizontal Tabulation hay Tab cho gọn. Nếu bạn xem tất cả vị trí kí tự nằm ngang trên trang in được đánh số bắt đầu từ 0, mã Tab thường mang nghĩa in kí tự tiếp theo ở vị trí nằm ngang liền kề là một bội của 8, như sau:
A B C
Đây là cách tiện lợi để giữ văn bản thẳng theo cột.
Thậm chí ngày nay, vài máy in phản hồi cho mã Form Feed (0Ch) bằng cách đẩy trang hiện tại ra và bắt đầu một trang mới.
Mã Backspace có thể được dùng để in kí tự ghép trên vài máy in cũ. Ví dụ, giả sử máy tính điều khiển TTY muốn hiển thị một chữ e thường với một dấu huyền, như này: è thì cần dùng mã hex 65 08 60.
Cho đến nay, các mã điều khiển quan trọng nhất là Carriage Return và Line Feed, vốn có cùng ý nghĩa với các mã Baudot tương ứng. Trên một số máy in máy tính đời cũ, mã Carriage Return dùng để đưa đầu in về lề trái của trang nhưng vẫn ở cùng một dòng, còn mã Line Feed dùng để đưa đầu in xuống dưới một dòng. Thông thường cần dùng cả hai mã này để chuyển sang dòng mới. Carriage Return có thể được dùng riêng lẻ để in đè lên một dòng đã có, còn Line Feed có thể được dùng riêng lẻ để nhảy xuống dòng tiếp theo mà không quay về lề trái.
Văn bản, ảnh, nhạc và video tất cả đều có thể lưu vào máy tính dưới dạng file (tệp), là tập hợp của các byte xác định bởi một cái tên. Những filename này thường gồm một tên mô tả thể hiện nội dung của file, và một phần mở rộng thường có 3 hay 4 chữ cái thể hiện kiểu file. File gồm các kí tự ASCII thường có phần mở rộng tên file là txt cho "text". ASCII không gồm mã cho chữ nghiêng hay đậm, hay các kiểu chữ và kích thước khác nhau. Những thứ màu mè này là đặc điểm của formatted text hay rich text (văn bản định dạng). ASCII chỉ dành cho plain text (văn bản thuần). Trên máy tính bàn Windows, chương trình Notepad có thể tạo file plain text; trên macOS, chương trình TextEdit làm điều tương tự (mặc dù đó không phải là hành vi mặc định). Cả 2 chương trình này cho phép bạn chọn loại font và kích thước, nhưng chỉ để xem thôi. Thông tin đó không được lưu cùng với chính văn bản.
Cả Notepad và TextEdit đều phản hồi nút Enter và Return để kết dòng hiện tại và di chuyển tới đầu dòng tiếp theo. Nhưng những chương trình này cũng thực hiện word wrapping (tự động xuống dòng): Khi bạn gõ và tới lề phải của cửa sổ, chương trình sẽ tự động tiếp tục nội dung gõ của bạn trên dòng tiếp theo và nó thật sự trở thành một phần của đoạn văn chứ không phải một dòng riêng lẻ. Bạn nhấn nút Enter hoặc Return để đánh dấu là cuối đoạn và bắt đầu một đoạn mới.
Khi bạn nhấn nút Enter hoặc Return, Notepad trên Windows thêm mã hex 0Dh và 0Ah vào file - kí tự cho Carriage Return và Line Feed. TextEdit trên macOS chỉ thêm 0Ah, Line Feed. Classic Mac OS (xuất hiện từ năm 1984 tới 2001) chỉ thêm 0Dh, Carriage Return. Tính bất nhất này vẫn còn là vấn đề khi một file tạo trên hệ điều hành này được đọc ở hệ điều hành khác. Trong những năm gần đây, các lập trình viên đã nghiên cứu để hạn chế tình trạng này, nhưng vẫn khá sốc - thậm chí là xấu hổ - vì vẫn chưa có tiêu chuẩn ngành máy tính nào để chỉ định giá trị cuối dòng hoặc cuối đoạn trong file plain text.
Ngay sau khi xuất hiện, ASCII trở thành tiêu chuẩn thống trị văn bản trong thế giới máy tính, nhưng với IBM "say no". Liên quan tới System/360, IBM đã phát triển bộ mã kí tự dành riêng cho nó tên là Extended BCD Interchange Code, hay EBCDIC, là một phần mở rộng 8 bit của mã 6 bit đời đầu tên là BCDIC, xuất phát từ mã dùng trong thẻ đục lỗ của IBM. Phong cách thẻ đục lỗ này - có khả năng lưu 80 kí tự của văn bản - được giới thiệu bởi IBM năm 1928 và được dùng hơn 50 năm.
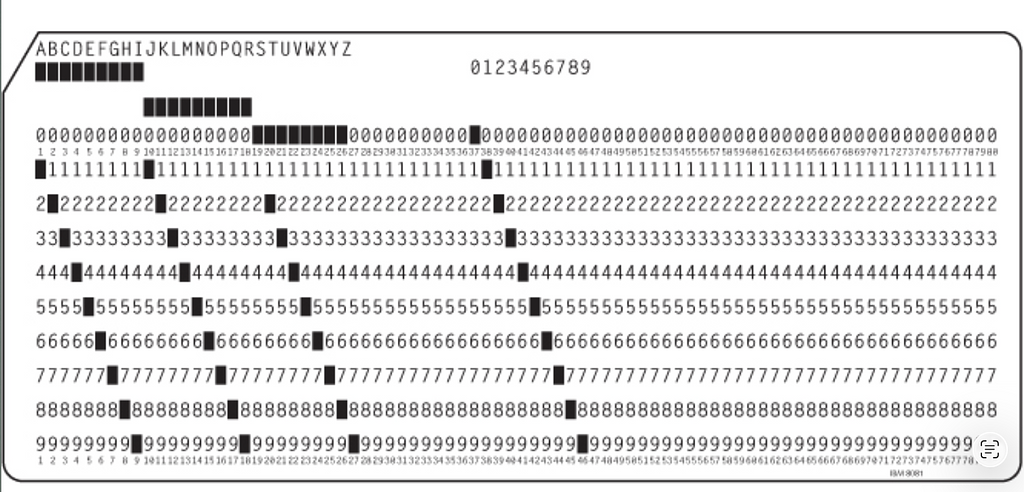
Hình chữ nhật đen là lỗ đóng lên thẻ. Thẻ đục lỗ có một vấn đề thực tiễn ảnh hưởng tới cách biểu diễn kí tự: Nếu có quá nhiều lỗ bị đục trên thẻ có thể gây mất độ bền kết cấu, bị rách, và làm máy bị kẹt.
Một kí tự được mã hoá trong thẻ đục lỗ bằng cách kết hợp một hay nhiều lỗ hình chữ nhật được đục theo một cột. Chính kí tự đó thường được in gần đầu thẻ. Mười hàng dưới được gọi là digit row (hàng số) và được xác định bởi số: hàng 0, hàng 1, và cứ thế tới hàng 9. Đây là những dấu tích còn sót lại của hệ thống máy tính làm việc trực tiếp với số thập phân. 2 hàng không đánh số gần đầu là zone row và được gọi là hàng 11 và hàng 12, chính là thứ ở trên cùng. Không có hàng 10.
Các mã ký tự EBCDIC là sự kết hợp giữa các lỗ vùng (zone punches) và các lỗ chữ số (digit punches). Các mã EBCDIC cho mười chữ số nằm trong khoảng từ F0h đến F9h. Các mã EBCDIC cho chữ cái in hoa được chia thành ba nhóm: từ C1h đến C9h, từ D1h đến D9h, và từ E2h đến E9h. Các mã EBCDIC cho chữ cái thường cũng được chia thành ba nhóm: từ 81h đến 89h, từ 91h đến 99h, và từ A2h đến A9h.
Trong ASCII, tất cả chữ hoa và thường nằm trong các chuỗi liên tục. Rất là tiện lợi để sắp xếp dữ liệu ASCII theo bảng chữ cái. EBCDIC, tuy nhiên, có lỗ hổng trong chuỗi các chữ cái, làm cho sắp xếp khó hơn. May mắn là ngày nay EBCDIC đơn thuần mang tính tham khảo lịch sử hơn là thứ bạn có thể bắt gặp trong đời sống cá nhân hoặc chuyên nghiệp.
Vào thời điểm ASCII đang được phát triển, bộ nhớ rất đắt đỏ. Nhiều người cảm thấy để tiết kiệm bộ nhớ, ASCII nên là mã 6 bit với kí tự shift để phân biệt chữ hoa thường. Một khi ý tưởng này bị từ chối, những người khác tin rằng ASCII nên là mã 8 bit vì có vẻ như là máy tính sẽ dùng kiến trúc 8 bit chứ không phải 7. Tất nhiên, 1 byte 8 bit giờ đã là tiêu chuẩn và mặc dù ASCII về mặt kĩ thuật là mã 7 bit, nó gần như phổ biến để lưu giá trị 8 bit.
Sự tương đồng giữa byte và kí tự ASCII chắc chắn là tiện lợi vì ta có thể đoán được bao nhiêu bộ nhớ máy tính một tài liệu văn bản cần chỉ bằng cách đếm kí tự. Ví dụ, Moby-Dick của Herman Melville hay The Whale có khoảng 1,25 triệu kí tự và do đó chiếm 1,25 triệu byte lưu trữ máy tính. Từ thông tin này, có thể suy ra được gần đúng số lượng chữ: Một chữ trung bình thường có 5 kí tự, cộng thêm dấu cách xuất hiện giữa các chữ, tính ra được khoảng 200 nghìn chữ trong Moby-Dick. Một file plain-text của Moby-Dick có thể được tải xuống từ trang Project Gutenberg (gutenberg.org) kèm với nhiều tác phẩm văn học cổ điển khác trong public domain. Mặc dù Project Gutenberg tiên phong trong việc đăng tải sách dạng plain text, nó cũng tạo sách với các định dạng e-book khác bao gồm cả HTML (Hypertext Markup Language).
Là một định dạng dùng cho trang web trên toàn cõi internet, HTML rõ ràng là định dạng rich text phổ biến nhất. HTML thêm các định dạng đẹp đẽ vào plain text bằng cách dùng các mẫu markup hay tag. Nhưng điều thú vị là HTML dùng các kí tự ASCII thông thường cho markup, nên một file HTML cũng là một file plain text bình thường. Khi xem như là plain text, HTML trông thế này:
This is some <b>bold</b> text, and this is some <i>italic</i> text.
Dấu ngoặc góc chỉ là mã ASCII 3Ch và 3Eh. Nhưng khi được dịch là HTML, một trình duyệt có thể hiển thị văn bản như sau:
This is some bold text, and this is some italic text.
Vẫn là nội dung cũ nhưng được render theo một cách khác. ASCII chắc chắn là tiêu chuẩn quan trọng nhất trong công nghiệp máy tính nhưng ngay từ đầu nó vẫn còn thiếu hụt. Vấn đề lớn nhất là American Standard Code for Information Interchange chỉ dành cho mỗi nước Mỹ! Thật sự thì ASCII gần như không phù hợp, thậm chí là với các quốc gia có ngôn ngữ chính thức là tiếng Anh. ASCII có dấu đô la nhưng dấu pound của Anh đâu rồi? Nó thất bải thảm hại với các chữ cái có dấu được dùng trong nhiều ngôn ngữ Tây Âu, còn chưa kể tới bảng chữ cái ngoài Latin dùng ở châu Âu gồm Hy Lạp, Arabic, Hebrew và Cyrillic hay Brahmi của Ấn Độ và Đông Nam Á, bao gồm Devanagari, Bengali, Thái và Tibetan. Và làm cách nào để mã 7 bit có thể xử lý được mười ngàn chữ tượng hình của Trung, Nhật, Hàn và mười ngàn chữ Hangul kì lạ của Hàn?
Gom hết tất cả ngôn ngữ của thế giới vào ASCII là một mục đích quá tham vọng vào năm 1960, nhưng nhu cầu cho các quốc gia khác vẫn được ghi nhớ mặc dù chỉ với các giải pháp sơ đẳng. Theo chuẩn ASCII được công bố, 10 mã ASCII (40h, 5Bh, 5Ch, 5Dh, 5Eh, 60h, 7Bh, 7Ch, 7Dh và 7Eh) có sẵn để định nghĩa lại cho các quốc gia khác. Thêm nữa, kí hiệu số (#) có thể được thay bằng kí hiệu pound của Anh (£) và dấu đô la ($) có thể thay bằng một dấu tiền tệ chung ($). Rõ ràng, việc thay thế các kí hiệu chỉ có ý nghĩa khi những người liên quan dùng chung một tài liệu chứa những mã mới này biết về rõ về chúng.
Vì nhiều hệ máy tính lưu kí tự bằng giá trị 8 bit nên có thể nghĩ tới việc phát minh ra thứ gì đó có tên là extended ASCII character set chứa 256 kí tự chứ không phải 128. Trong một bộ kí tự như vậy, 128 mã đầu tiên với giá trị hex từ 00h tới 7Fh, được định nghĩa như trong ASCII, nhưng 128 mã tiếp theo (80h tới FFh) có thể là bất cứ thứ gì bạn muốn. Kĩ thuật này được dùng để định nghĩa mã kí tự bổ sung cho chữ cái có dấu và chữ khác hệ Latin. Nhưng không may, ASCII lại được mở rộng nhiều lần bằng nhiều phương thức khác nhau.
Khi Windows của Microsoft lần đầu được phát hành, nó hỗ trợ phần mở rộng của ASCII mà Microsoft gọi là bộ kí tự ANSI, mặc dù nó không được chứng nhận bởi Amerrican Nation Standards Institute. Các kí tự bổ sung cho mã từ A0h tới FFh hầu hết là các kí hiệu hữu dụng và chữ cái có dấu thường thấy trong ngôn ngữ châu Âu. Trong bảng này, nửa byte bậc cao (high-order nibble) của mã ký tự hex được hiển thị ở hàng trên cùng; còn nửa byte bậc thấp (low-order nibble) được hiển thị ở cột bên trái:
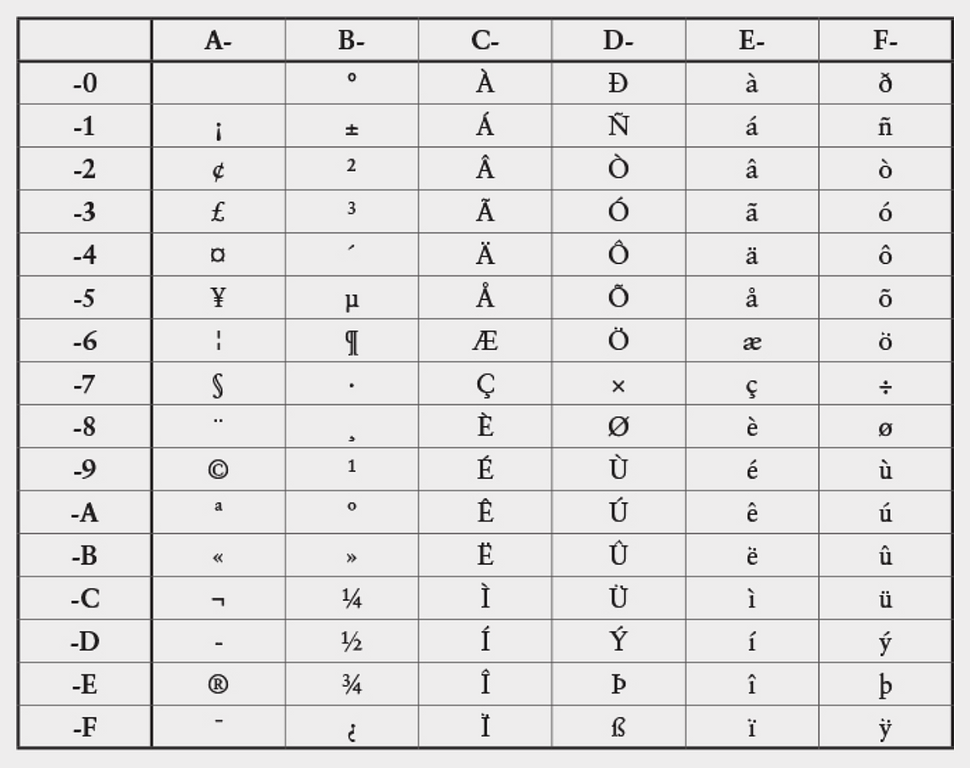
Kí tự cho mã A0h được định nghĩa là no-break space. Thường khi một chương trình máy tính định dạng văn bản theo các hàng và đoạn, nó tách dòng tại kí tự space, là mã ASCII 20h. Mã A0h được xem như là một space nhưng không thể xuống dòng. Nó có thể dùng khi viết ngày ví dụ như trong February 2 để cho February và 2 không bị tách ra 2 dòng giúp dễ đọc hơn.
Mã ADh được định nghĩa là một soft hyphen (gạch nối mềm). Nó được dùng để tách các âm tiết trong một chữ. Chỉ xuất hiện trên trang in khi cần phải tách một chữ ra 2 dòng (thường xuất hiện trong tiếng Anh, tiếng Việt mình ít gặp).
Bộ ký tự ANSI trở nên phổ biến vì nó là một phần của Windows, nhưng thực ra nó chỉ là một trong rất nhiều phần mở rộng khác nhau của ASCII được định nghĩa qua nhiều thập kỷ. Để phân biệt rõ ràng, các bộ này dần dần được gán thêm các con số và những định danh khác. Bộ kí tự ANSI của Windows trở thành tiêu chuẩn International Standards Organization được biết là ISO-8859-1 hay Latin Alphabet No. 1. Khi bộ kí tự này tự mở rộng để thêm vào kí tự cho các mã từ 80h tới 9Fh, nó trở thành Windows-1252:
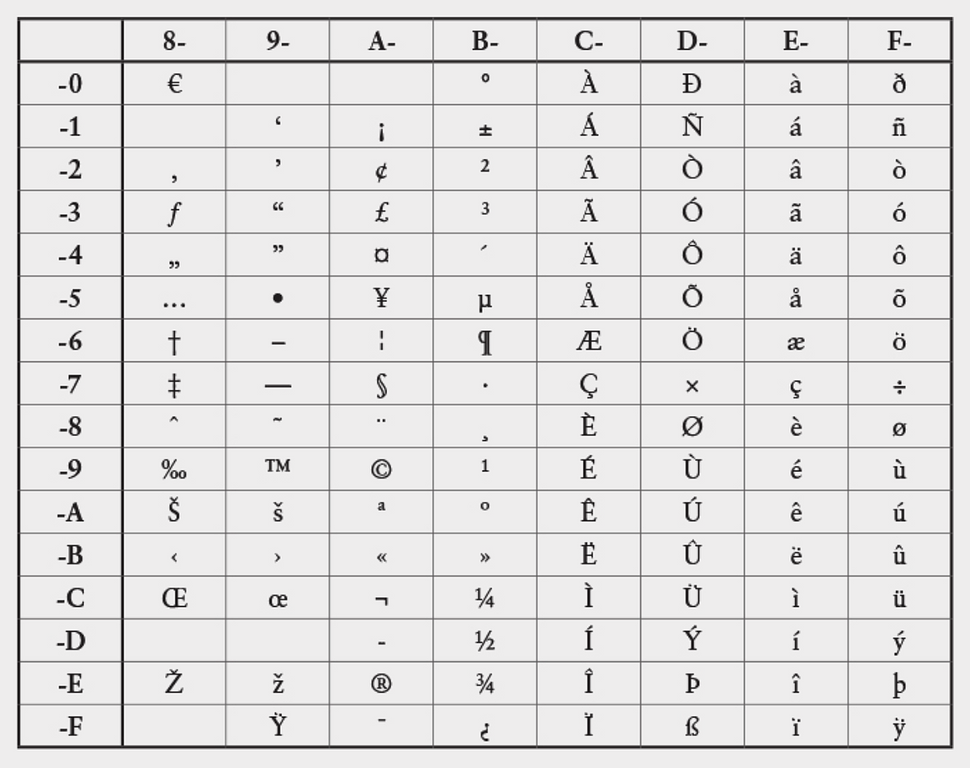
Số 1252 được gọi là bộ định danh trang mã (code page identifier), một thuật ngữ bắt nguồn từ IBM để phân biệt với các phiên bản khác của EBCDIC. Vài code page liên hệ với quốc gia yêu cầu kí tự dấu của riêng nó và thậm chí cả bộ bảng chữ cái, như là Greek, Cyrillic và Arabic. Để render dữ liệu kí tự đúng, cần phải biết code page liên quan là gì. Dần dà nó trở thành một phần quan trọng nhất trên Internet nơi thông tin ở đầu file HTML (header) thể hiện code page dùng để tạo trang web.
ASCII cũng được mở rộng theo nhiều hướng triệt để để mã hoá chữ tượng hình của Trung, Nhật, Hàn. Trong một mã hoá phổ biến - gọi là Shift-JIS (Japanese Industrial Standard)- mã từ 81h tới 9Fh biểu diễn byte đầu của mã kí tự 2 byte. Theo cách này Shift-JIS cho phép mã hóa khoảng 6.000 ký tự bổ sung. Không may là không phải chỉ có mỗi Shift-JIS áp dụng kỹ thuật này. Ba bộ ký tự hai byte (DBCS) tiêu chuẩn khác cũng đã trở nên phổ biến ở châu Á.
Sự tồn tại của nhiều bộ ký tự hai byte không tương thích với nhau chỉ là một trong nhiều vấn đề của chúng. Một vấn đề khác là một số kí tự — cụ thể là các kí tự ASCII thông thường — được biểu diễn bằng mã 1 byte, trong khi hàng nghìn biểu tượng (ideograph) lại được biểu diễn bằng mã 2 byte. Điều này khiến cho việc làm việc với các bộ kí tự này trở nên khó khăn.
Nếu bạn cảm thấy chuyện này nghe có vẻ rối rắm, thì bạn không phải là người duy nhất. Vậy liệu có ai có thể đưa ra một giải pháp không?
Dưới giả định là sẽ thích hợp hơn khi chỉ có một hệ mã hoá kí tự không rối rắm phù hợp cho tất cả ngôn ngữ trên thế giới, vài công ty máy tính lớn hợp tác cùng nhau vào năm 1988 và bắt đầu phát triển một bộ thay thế cho ASCII tên là Unicode. Trong khi ASCII là mã 7 bit, Unicode là mã 16 bit. (Hay ít nhất đó là ý tưởng ban đầu) Trong concept ban đầu, mỗi và chỉ một kí tự trong Unicode cần 2 byte, với mã kí tự bắt đầu từ 0000h tới FFFFh để đại diện 65.535 kí tự khác nhau. Nó được xem là đủ cho tất cả ngôn ngữ thế giới được dùng cho giao tiếp máy tính và vẫn còn room để mở rộng.
Unicode không bắt đầu từ con số 0. 128 kí tự đầu tiên của Unicode - code 0000h tới 007Fh- giống với kí tự ASCII. Cũng vậy, mã Unicode 00A0h tới 00FFh giống với phần mở rộng Latin Alphabet No. 1 của ASCII mà tôi đã mô tả trước đó. Các tiêu chuẩn quốc tế khác cũng được tích hợp vào Unicode.
Mặc dù mã Unicode chỉ là một giá trị hex, cách chuẩn để thể hiện nó là bắt đầu giá trị với một chữ U hoa và một dấu cộng. Đây là vài kí tự biểu diễn trong Unicode:
Mã Hex Kí tự Mô tả U+0041 A Chữ in hoa Latin A U+00A3 £ Dấu Bảng Anh U+03C0 π Chữ Hi Lạp cho Pi U+0416 Ж Chữ in hoa Sla-vơ Zhe U+05D0 א Chữ Hebrew Alef U+0BEB ௫ Chữ số Tamil 5 U+2018 ‘ Dấu nháy đơn trái U+2019 ’ Dấu nháy đơn phải U+20AC € Kí hiệu euro U+221E ∞ Vô cực
Còn nhiều hơn nữa trong website quản lý bởi Unicode Consortium, unicode.org, nó sẽ cho bạn một chuyến tham quan kì thú để thấy được sự phong phú của chữ viết và kí hiệu trên thế giới. Kéo xuống cuối trang chủ và nhấp vào Code Charts để đến một vùng ảnh của nhiều kí tự mà bạn chưa tin nổi là tồn tại.
Nhưng đi từ mã kí tự 8 bit sang mã 16 bit gây ra vấn đề của riêng nó: Những máy tính khác nhau đọc giá trị 16 bit theo các cách khác nhau. Ví dụ xem xét 2 byte sau:
Nhưng đi từ mã kí tự 8 bit sang mã 16 bit gây ra vấn đề của riêng nó: Những máy tính khác nhau đọc giá trị 16 bit theo các cách khác nhau. Ví dụ xem xét 2 byte sau:
20h ACh
Một số máy tính sẽ đọc chuỗi đó như một giá trị 16 bit là 20ACh, tức mã Unicode của ký hiệu đồng euro. Những máy tính này được gọi là máy big-endian, nghĩa là byte có trọng số lớn nhất (đầu “to”) được đặt trước. Những máy tính khác là máy little-endian. (Thuật ngữ này bắt nguồn từ Gulliver’s Travels, trong đó Jonathan Swift mô tả một cuộc trang cãi về việc nên đập trứng luộc lòng đào ở đầu nào.) Các máy little-endian sẽ đọc giá trị đó là AC20h, mà trong Unicode tương ứng với ký tự 갠 trong bảng chữ cái Hangul của tiếng Hàn.
Để khắc phục vấn đề này, Unicode định nghĩa một ký tự đặc biệt gọi là đánh dấu thứ tự byte (byte order mark, hay BOM), có mã là U+FEFF. Ký tự này được đặt ở đầu một file gồm các giá trị Unicode 16 bit. Nếu hai byte đầu tiên là FEh và FFh, thì file đó dùng thứ tự big-endian. Nếu chúng là FFh và FEh thì dùng thứ tự little-endian.
Vào giữa những năm 1990, đúng vào thời điểm Unicode bắt đầu được chấp nhận rộng rãi, việc vượt ra ngoài giới hạn 16 bit trở nên cần thiết để bao gồm cả những hệ chữ đã tuyệt chủng nhưng vẫn cần được biểu diễn vì lý do lịch sử, cũng như để bổ sung vô số kí hiệu mới. Một trong số chúng chính là những kí tự phổ biến và thú vị tên là emoji.
Vào lúc đang viết dòng này (2021), Unicode đã mở rộng ra 21 bit với giá trị tới U+10FFFF, có khả năng hỗ trợ lên đến hơn 1 triệu kí tự khác nhau. Đây là vài kí tự không thể đạt được với mã 16 bit:
Mã Hex Kí tự Mô tả U+1302C 𓀬 Hình Ai cập A039 U+1F025 🀥 Hình mạt chược U+1F3BB 🎻 Violin U+1F47D 👽 Alien U+1F614 😔 Mặt trầm ngâm U+1F639 😹 Mặt mèo cười ra nước mắt
Việc đưa emoji vào Unicode trông có vẻ phù phiếm, nhưng điều đó chỉ đúng nếu bạn cho rằng việc một emoji được nhập trong tin nhắn văn bản lại hiển thị thành một thứ hoàn toàn khác trên điện thoại của người nhận là chấp nhận được. Khi đó, những hiểu lầm có thể xảy ra, và các mối quan hệ cũng có thể tan vỡ!
Tất nhiên, nhu cầu sử dụng Unicode của mỗi người là khác nhau. Đặc biệt khi hiển thị biểu tượng của các ngôn ngữ châu Á, việc sử dụng Unicode một cách rộng rãi là điều cần thiết. Những tài liệu và trang web khác thì có nhu cầu khiêm tốn hơn. Nhiều trường hợp vẫn có thể hoạt động hoàn toàn ổn với ASCII “cũ kỹ” quen thuộc. Vì lý do đó, đã có nhiều phương pháp khác nhau được định nghĩa để lưu trữ và truyền tải văn bản Unicode. Chúng được gọi là các định dạng chuyển đổi Unicode, hay UTF (Unicode Transformation Formats).
Định dạng chuyển đổi Unicode dễ hiểu nhất là UTF-32. Tất cả kí tự Unicode được định nghĩa là giá trị 32 bit. 4 byte cần thiết cho mỗi kí tự có thể được xác định trong cả little-endian order và big-endian order.
Hạn chế của UTF-32 là nó dùng rất nhiều dấu cách. Một file plain text chứa nội dung của Mody Dick sẽ tăng kích thước từ 1,25 triệu byte trong ASCII lên 5 triệu byte trong Unicode. Và Unicode chỉ dùng 21 trong 32 bit nên có 11 bit lãng phí cho mỗi kí tự. Một dạng hứa hẹn hơn là UTF-16. Với định dạng này, gần hết các kí tự được định nghĩa với 2 byte, nhưng kí tự với mã trên U+FFFF được định nghĩa với 4 byte. Một vùng trong tài liệu Unicode gốc từ U+D800 tới U+DFFF bỏ phí không gán cho gì bởi mục đích này.
Định dạng chuyển đổi Unicode quan trọng nhất là UTF-8, giờ được dùng trên toàn cõi mạng. Một thống kê gần đây cho thấy 97% tất cả các trang web hiện nay sử dụng UTF-8. Đây gần như là mức độ của một chuẩn phổ quát mà bạn có thể mong muốn. Các file plain text của Project Gutenberg đều dùng UTF-8. Windows Notepad và macOS TextEdit cũng lưu file ở định dạng UTF-8 theo mặc định.
UTF-8 là một sự thoả hiệp giữa linh hoạt và ngắn gọn. Ưu điểm lớn nhất của UTF-8 là nó tương thích ngược với ASCII. Có nghĩa là một file chỉ toàn mã ASCII 7 bit tự động lưu byte là một file UTF-8.
Để sự tương thích này thành hiện thực, tất cả kí tự Unicode được lưu với 2, 3, 4 byte phụ thuộc vào giá trị của chúng. Bảng sau tóm tắt cách UTF-8 hoạt động:
Khoảng Unicode Số Bit Chuỗi Byte U+0000 tới U+007F 7 0xxxxxxx U+0080 tới U+07FF 11 110xxxxx 10xxxxxx U+0800 tới U+FFFF 16 1110xxxx 10xxxxxx 10xxxxxx U+10000 tới U+10FFFF 21 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
Đối với các khoảng mã hiển thị ở cột đầu tiên, mỗi ký tự được định danh duy nhất bằng một số bit như thể hiện ở cột thứ hai. Sau đó, các bit này được thêm tiền tố bằng các bit 1 và 0, như minh họa ở cột thứ ba, để tạo thành một chuỗi các byte. Số lượng ký tự x trong cột thứ ba tương ứng với số lượng bit được nêu ở cột thứ hai.
Hàng đầu tiên của bảng cho biết rằng nếu ký tự thuộc tập mã ASCII gốc 7 bit, thì cách mã hóa UTF-8 của ký tự đó là một bit 0 theo sau bởi 7 bit này, tức là giống hệt mã ASCII ban đầu.
Các ký tự có giá trị Unicode từ U+0080 trở lên cần 2 byte hoặc nhiều hơn. Ví dụ, ký hiệu bảng Anh (£) có mã Unicode là U+00A3. Vì giá trị này nằm trong khoảng từ U+0080 đến U+07FF, hàng thứ hai của bảng cho thấy nó được mã hóa trong UTF-8 bằng 2 byte. Với các giá trị trong khoảng này, chỉ cần sử dụng 11 bit có trọng số thấp nhất để suy ra cách mã hóa 2 byte, như minh họa dưới đây:
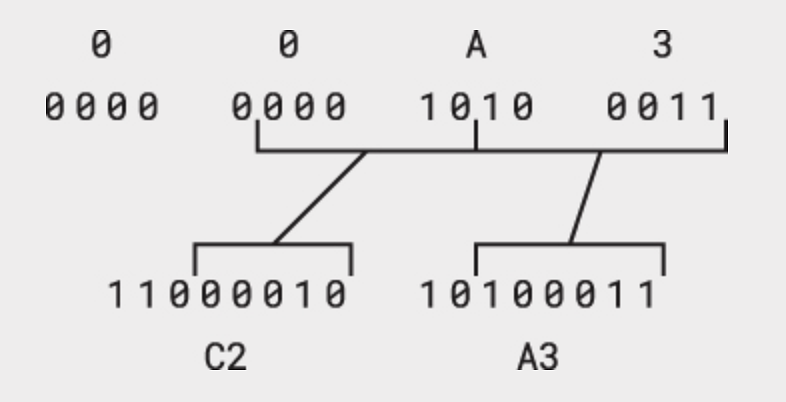
Giá trị Unicode của 00A3 được trình bày ở trên cùng của sơ đồ. Mỗi chữ số trong 4 chữ số hex tương ứng với giá trị 4 bit xuất hiện ngay bên dưới. Ta biết giá trị là 07FFh hoặc ít hơn, có nghĩa là 5 bit quan trọng nhất sẽ là 0 và có thể bỏ qua được. 5 bit tiếp theo bắt đầu với 110 (như thấy ở phía dưới hình) để tạo thành byte C2h. 6 bit ít quan trọng nhất được thêm vào đầu 10 để thành byte A3h.
Do đó, trong UTF-8 2 byte C2h và A3h đại diện cho kí hiệu £ Anh. Cần tới 2 byte để mã hoá trong khi cơ bản chỉ cần 1 byte thông tin là đủ rồi, nhưng như vậy là cần thiết để toàn bộ UTF-8 hoạt động.
Dưới đây là một ví dụ khác. Chữ cái Hebrew א (alef) là U+05D0 trong Unicode. Lần nữa, giá trị đó nằm giữa U+0080 và U+07FF, nên hàng thứ 2 của bảng được dùng tới. Quy trình tương tự như của kí tự £:
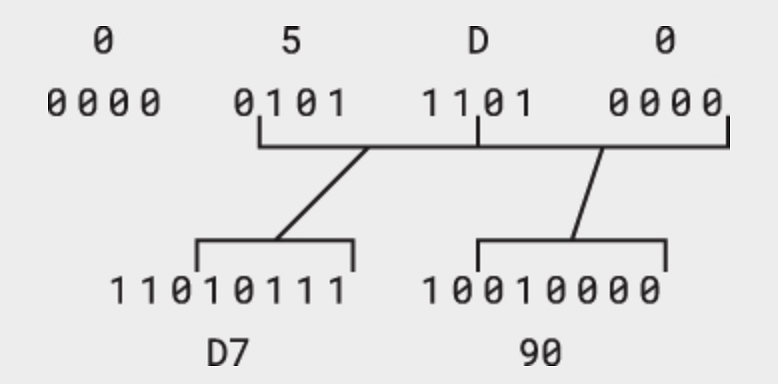
5 bit đầu của giá trị 05D0h có thể bỏ qua; 5 bit tiếp theo bắt đầu với 110, và 6 bit ít quan trọng nhất bắt đầu với 10 để tạo thành byte UTF-8 D7h và 90h.
Dù cho hình ảnh hiển thị có khác nhau thì emoji Mặt Mèo Cười Ra Nước Măt được biểu diễn bằng U+1F639 trong Unicode, có nghĩa UTF-8 là một chuỗi 4 byte. Sơ đồ này cho thấy cách 4 byte này được lắp từ 21 bit của mã gốc:
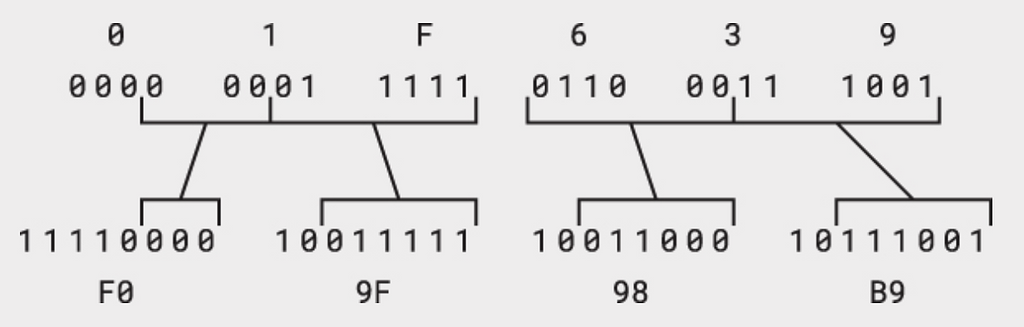
Việc biểu diễn kí tự bằng số lượng byte thay đổi, UTF-8 phần nào làm mất đi vẻ đẹp và sự thuần khiết của Unicode. Trước đây, những cơ chế tương tự khi được dùng cùng với ASCII đã gây ra không ít vấn đề và nhầm lẫn. UTF-8 không hoàn toàn miễn nhiễm với các rắc rối, nhưng nó được định nghĩa một cách rất thông minh. Khi một tệp UTF-8 được giải mã, mỗi byte đều có thể được nhận diện một cách khá chính xác:
- Nếu byte bắt đầu bằng 0, nó là mã kí tự ASCII 7 bit
- Nếu byte bắt đầu bằng 10, nó là một phần của chuỗi các byte biểu diễn một mã kí tự multibyte, nhưng nó không phải là byte đầu tiên trong chuỗi đó.
- Còn lại, byte bắt đầu với ít nhất 2 bit 1, và nó là byte đầu tiên của mã kí tự multibyte. Tổng số byte cho mã kí tự này được thể hiện bởi số lượng bit 1 mà byte đầu tiên này bắt đầu trước bit 0 đầu tiên. Có thể là 2, 3 hoặc 4.
Hãy thử chuyển UTF-8 thêm lần nữa: kí tự dấu nháy đơn bên phải là U+2019 (’). Nó cần tham vấn hàng thứ 3 của bảng bởi vì giá trị này nằm giữa U+0800 và U+FFFF. Đại diện UTF-8 là 3 byte:
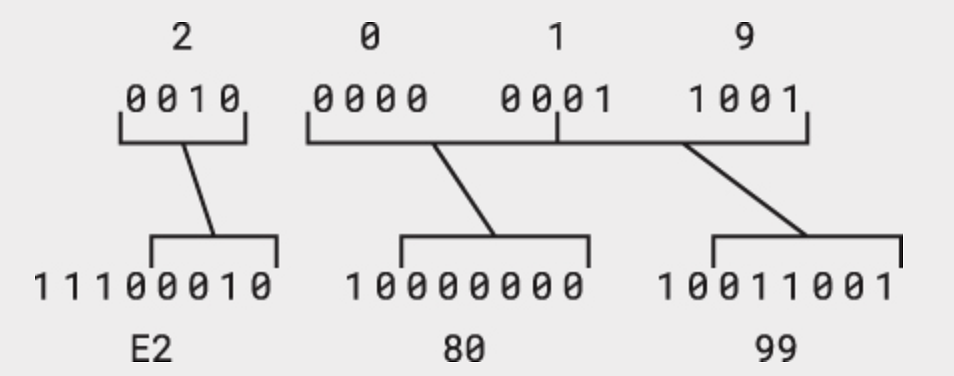
Tất cả bit của số Unicode gốc cần để tạo thành 3 byte. 4 bit đầu tiên bắt đầu với 1110, 6 bit tiếp theo với 10, và 6 bit ít quan trọng nhất cũng với 10. Kết quả là chuỗi 3 byte E2h, 80h và 99h.
Giờ có thể nhìn ra được vấn đề với email mà tôi đề cập ở đầu chương với dòng tiêu đề
We⯙ve received your payment, thanks.
Chữ đầu tiên rõ ràng là “We’ve” nhưng dấu rút gọn được dùng không phải là dấu ngoặc đơn ASCII kiểu cũ (ASCII 27h hay Unicode U+0027) mà là Unicode Right Single Quotation Mark màu mè hơn, như ta vừa thấy được mã hoá trong UTF-8 với 3 byte E2h, 80h và 99h.
Tới giờ, không có vấn đề gì. Nhưng file HTML trong email này nói rằng nó đang dùng bộ kí tự "Windows-1252". Đáng lẽ nó phải nói "UTF-8" vì đó là cách mà văn bản được mã hoá. Nhưng vì file HTML này bảo là "windows-1252" nên chương trình email của tôi dùng bộ kí tự windows-1252 để dịch 3 byte này. Kiểm tra lại trong bảng mã Windows-1252 ở trang 162 để tự xác nhận là 3 byte E2h, 80h và 99h thật sự gắn liền với kí tự â, ¯ và ™, chính là các kí tự kì lạ trong email.
Bí ẩn đã được phát hiện.
Bằng cách mở rộng khả năng tính toán để có được trải nghiệm đa văn hoá và phổ biến toàn cầu, Unicode đã thành một tiêu chuẩn cực kì quan trọng. Nhưng cũng như bất cứ thứ gì, nó chỉ hoạt động khi được dùng đúng cách.