Trong hai năm 1936 và 1937, nhà văn người Anh Herbert George Wells đã có một loạt buổi diễn thuyết trước công chúng về một chủ đề khá kì lạ. Lúc bấy giờ, H. G. Wells đã ngoài bảy mươi. Những cuốn tiểu thuyết khoa học viễn tưởng đình đám của ông—Cỗ máy Thời gian, Hòn đảo của Tiến sĩ Moreau, Người Tàng hình, và Đại chiến Thế giới—đã được xuất bản từ những năm 1890 và đưa ông lên đỉnh vinh quang. Thế nhưng Wells đã chuyển mình thành một trí thức của công chúng, người suy nghĩ sâu sắc về các vấn đề xã hội và chính trị rồi chia sẻ chúng với mọi người.
Các bài giảng của Wells trong hai năm đó đã được gom lại và xuất bản thành sách vào năm 1938 với tựa đề World Brain (Não Thế giới). Trong những buổi nói chuyện này, Wells đề xuất một loại bách khoa toàn thư, nhưng không phải loại làm ra để bán dạo gõ cửa từng nhà. Cuốn World Encyclopedia này sẽ cô đọng tri thức toàn cầu theo một cách chưa từng có.
Đó là thời kì bấp bênh ở châu Âu: Ký ức về cuộc Đại chiến chỉ mới hai thập kỷ trước vẫn còn hằn sâu, vậy mà châu Âu dường như lại đang lao đầu vào một cuộc xung đột nhuốm máu cả lục địa khác. Là một người lạc quan và theo chủ nghĩa không tưởng, Wells tin rằng khoa học, tính hợp lý và tri thức là những công cụ tốt nhất để dẫn dắt thế giới tiến tới tương lai. Cuốn Bách khoa Toàn thư Thế giới mà ông đề xuất sẽ chứa đựng
... những khái niệm chủ đạo của trật tự xã hội chúng ta, những nét chính và chi tiết quan trọng trong mọi lĩnh vực tri thức, một bức tranh chính xác và chi tiết hợp lý về vũ trụ, một lịch sử tổng quát về thế giới, và... một hệ thống tham chiếu đáng tin cậy và hoàn chỉnh tới các nguồn tri thức căn bản.
Tóm lại, nó sẽ mang đến "một cách diễn giải chung về thực tại" và một sự "thống nhất về mặt tư duy."
Một cuốn bách khoa toàn thư như vậy cần được cập nhật liên tục với vốn tri thức về thế giới không ngừng mở rộng, nhưng trong quá trình phát triển, nó sẽ trở thành
... một dạng trung tâm trao đổi tư duy cho tâm trí, một kho chứa nơi tri thức và ý tưởng được tiếp nhận, phân loại, tóm tắt, tiêu hóa, làm rõ và so sánh... Nó sẽ tạo thành khởi đầu vật chất của một Bộ não Thế giới thực thụ.
Những chiếc máy tính kỹ thuật số phôi thai đầu tiên mới chỉ đang được chế tạo vào những năm 1930, và có lẽ Wells chẳng hề hay biết gì về chúng, nên ông không còn cách nào khác là hình dung cuốn bách khoa toàn thư này dưới dạng những cuốn sách: "hai mươi, ba mươi hoặc bốn mươi tập." Nhưng ông cũng rất rành về công nghệ vi phim (microfilm) đang nổi lên lúc bấy giờ:
Có vẻ như trong tương lai gần, chúng ta sẽ có những thư viện lưu trữ vi mô, nơi bản chụp của mọi cuốn sách và tài liệu quan trọng trên thế giới sẽ được cất giữ và dễ dàng lấy ra cho sinh viên tham khảo... Thời điểm đang đến rất gần khi bất kỳ sinh viên nào, ở bất kỳ đâu trên thế giới, cũng có thể ngồi với chiếc máy chiếu trong chính phòng học của mình theo ý thích để xem xét bất kỳ cuốn sách, bất kỳ tài liệu nào, trong một bản sao y hệt.
Nhìn xa trông rộng nhỉ!
Chưa đầy một thập kỷ sau, vào năm 1945, kỹ sư và nhà phát minh Vannevar Bush cũng có một tầm nhìn tương tự, nhưng tiên tiến hơn một chút.
Bush đã ghi dấu ấn trong lịch sử điện toán. Bắt đầu từ năm 1927, Bush và các sinh viên của ông tại khoa kỹ thuật điện của Viện Công nghệ Massachusetts (MIT) đã chế tạo một máy phân tích vi phân (differential analyzer), một máy tính tương tự (analog computer) sơ khai chuyên giải các phương trình vi phân. Đến đầu những năm 1930, ông đã là trưởng khoa kỹ thuật và là phó chủ tịch tại MIT.
Cáo phó của Bush năm 1974 trên tờ New York Times đã vinh danh ông là "hình mẫu của một kỹ sư—một người làm gì cũng được", dù đó là giải quyết các vấn đề kỹ thuật hay dẹp bỏ những rườm rà của bộ máy hành chính chính phủ. Trong Thế chiến thứ hai, Bush phụ trách điều phối hơn 30.000 nhà khoa học và kỹ sư cho nỗ lực chiến tranh, bao gồm cả việc giám sát Dự án Manhattan chế tạo quả bom nguyên tử đầu tiên. Trong nhiều thập kỷ, Bush là người ủng hộ mạnh mẽ việc đưa các nhà khoa học và kỹ sư tham gia vào chính sách công.
Gần cuối Thế chiến thứ hai, Bush đã viết một bài báo nay đã thành nổi tiếng cho ấn bản tháng 7 năm 1945 của tạp chí Atlantic Monthly. Mang tựa đề "As We May Think" (Cách chúng ta tư duy), nhìn lại thì nó có vẻ tiên tri. Một phiên bản rút gọn của bài báo này đã được đăng trên tạp chí Life số tháng 9 kèm theo một số hình minh họa bay bổng.
Giống như Wells, Bush tập trung vào thông tin và sự khó khăn khi phải bắt kịp nó:
Có một núi nghiên cứu ngày càng cao. Nhưng có một sự gia tăng bằng chứng cho thấy chúng ta đang sa lầy khi sự chuyên môn hóa ngày càng mở rộng. Nhà nghiên cứu bị choáng ngợp bởi những phát hiện và kết luận của hàng ngàn công nhân khác—những kết luận mà anh ta không tìm được thời gian để nắm bắt, huống hồ là để ghi nhớ, khi chúng xuất hiện... Khó khăn dường như không phải nằm ở chỗ chúng ta xuất bản quá nhiều nếu xét đến phạm vi và sự đa dạng của các mối quan tâm hiện tại, mà đúng hơn là việc xuất bản đã vượt xa khả năng của chúng ta trong việc tận dụng thực sự những gì được ghi chép lại. Tổng hòa kinh nghiệm của nhân loại đang được mở rộng với tốc độ chóng mặt, và phương tiện chúng ta sử dụng để luồn lách qua mê cung hậu quả nhằm tìm đến một mục quan trọng nhất thời thì vẫn giống hệt như thời của những chiếc thuyền buồm cánh vuông.
Bush nhận thức được công nghệ đang phát triển vũ bão có thể giúp ích cho các nhà khoa học trong tương lai. Ông hình dung ra một chiếc máy ảnh đeo trên trán có thể kích hoạt bất cứ khi nào cần ghi lại thứ gì đó. Ông nói về vi phim, về "truyền bản sao" (facsimile transmission - tức là máy fax) tài liệu, và về những cỗ máy có thể ghi âm trực tiếp giọng nói con người rồi chuyển thành văn bản. Nhưng về cuối bài viết, Bush chỉ ra một vấn đề còn tồn đọng: "... vì chúng ta có thể mở rộng hồ sơ một cách khủng khiếp; thế nhưng ngay cả trong khối lượng đồ sộ hiện tại, ta vẫn khó lòng mà tra cứu nó." Hầu hết thông tin được sắp xếp và lập chỉ mục theo bảng chữ cái, nhưng rõ ràng thế là chưa đủ:
Tâm trí con người không hoạt động theo kiểu đó. Nó hoạt động bằng sự liên tưởng. Cầm một món đồ trong tay, nó lập tức chuyển sang món tiếp theo được gợi ý bởi sự liên kết các suy nghĩ, tuân theo một mạng lưới chằng chịt các dấu vết được lưu giữ bởi các tế bào não.
Bush mường tượng ra một cỗ máy, một "hồ sơ và thư viện cá nhân được cơ giới hóa", một chiếc bàn làm việc tinh xảo lưu trữ vi phim và giúp việc truy cập trở nên dễ dàng. Và ông đặt tên cho nó: "memex".
Phần lớn nội dung của memex được mua trên vi phim sẵn sàng để chèn vào. Sách đủ loại, tranh ảnh, tạp chí định kỳ hiện tại, báo chí, cứ thế được thu thập và thả vào đúng vị trí. Thư từ kinh doanh cũng đi theo con đường tương tự. Và có cả điều khoản để nhập trực tiếp. Trên đỉnh memex là một mặt kính trong suốt. Các ghi chú viết tay, ảnh, bản ghi nhớ, đủ mọi thứ được đặt lên đó. Khi một món đã vào vị trí, việc nhấn một đòn bẩy sẽ khiến nó được chụp ảnh lại vào khoảng trống tiếp theo trong một phần của memex...
Nhưng quan trọng nhất, các ghi chú bên lề và bình luận có thể được thêm vào các tài liệu này và liên kết với nhau bằng tính năng "lập chỉ mục liên tưởng" (associative indexing).
Đây là tính năng cốt lõi của memex. Quá trình buộc hai mục lại với nhau mới là điều quan trọng... Hơn nữa, khi vô số mục đã được nối lại với nhau tạo thành một lối mòn, chúng có thể được xem xét lần lượt, nhanh hay chậm, bằng cách gạt một đòn bẩy giống như loại dùng để lật các trang sách. Giống hệt như thể các mục vật lý đã được tập hợp lại từ những nguồn cách xa nhau và đóng lại với nhau để tạo thành một cuốn sách mới... Những hình thức bách khoa toàn thư hoàn toàn mới sẽ xuất hiện, được làm sẵn với một mạng lưới các lối mòn liên tưởng chạy xuyên qua chúng, sẵn sàng để thả vào memex và được khuếch đại ở đó.
Bush thậm chí còn dự đoán được sự tiện lợi của những con người lười biếng khi không bị ép buộc phải nhớ bất cứ thứ gì, bởi vì người dùng cỗ máy này "có thể giành lại đặc quyền được phép quên đi vô số thứ mà anh ta không cần phải có ngay trong tầm tay, với một sự đảm bảo rằng anh ta có thể tìm lại chúng nếu chúng tỏ ra quan trọng."
Năm 1965, hai thập kỷ sau khi Bush viết về memex, viễn cảnh hiện thực hóa giấc mơ này dưới dạng máy tính đang dần trở nên khả thi. Kẻ nhìn xa trông rộng về máy tính Ted Nelson (sinh năm 1937) đã tiếp nhận thách thức hiện đại hóa memex trong một bài báo có tựa đề "Xử lý Thông tin Phức tạp: Một Cấu trúc Tệp cho cái Phức tạp, cái Đang thay đổi và cái Vô định," xuất bản trong ACM '65, kỷ yếu của một hội nghị thuộc Hiệp hội Máy tính (Association for Computing Machinery). Phần tóm tắt bắt đầu bằng:
Các kiểu cấu trúc tệp cần thiết nếu chúng ta muốn sử dụng máy tính cho các hồ sơ cá nhân và như một phần phụ trợ cho sự sáng tạo, có đặc điểm hoàn toàn khác biệt so với những gì thường thấy trong xử lý dữ liệu khoa học và kinh doanh. Chúng cần cung cấp khả năng cho các sắp xếp phức tạp và mang tính cá nhân, khả năng thay đổi toàn diện, các lựa chọn chưa được quyết định, và hệ thống tài liệu nội bộ thấu đáo.
Nhắc đến bài viết của Bush về memex, Nelson quả quyết "Phần cứng đã sẵn sàng" cho việc hiện thực hóa trên máy tính. Cấu trúc tệp mà ông đề xuất vừa đầy tham vọng vừa cám dỗ, và ông cần phải phát minh ra một từ mới toanh để mô tả nó:
Cho phép tôi giới thiệu với thế giới từ "hypertext" (siêu văn bản) để chỉ một khối tài liệu viết hoặc hình ảnh được kết nối với nhau theo một cách phức tạp đến mức không thể trình bày hoặc biểu diễn thuận tiện trên giấy. Nó có thể chứa các bản tóm tắt, hoặc bản đồ về nội dung và mối tương quan của chúng; nó có thể chứa các chú thích, phần bổ sung và chú thích chân trang từ các học giả đã nghiên cứu nó. Cho phép tôi đề xuất rằng một đối tượng và hệ thống như vậy, nếu được thiết kế và quản lý đúng đắn, có thể mang lại tiềm năng to lớn cho giáo dục, tăng cường phạm vi lựa chọn, cảm giác tự do, động lực và khả năng nắm bắt trí tuệ của học sinh. Một hệ thống như vậy có thể phát triển vô tận, dần dần bao gồm ngày càng nhiều tri thức được viết ra của thế giới. Tuy nhiên, cấu trúc tệp bên trong của nó sẽ phải được xây dựng để chấp nhận sự phát triển, sự thay đổi và những sắp xếp thông tin phức tạp.
Từ những bài viết này của H. G. Wells, Vannevar Bush, và Ted Nelson, rõ ràng là ít nhất cũng có vài người đã nghĩ về internet từ rất lâu trước khi nó trở nên khả thi.
Việc giao tiếp giữa các máy tính qua những khoảng cách xa xôi là một nhiệm vụ khó khăn. Bản thân internet bắt nguồn từ một nghiên cứu của Bộ Quốc phòng Hoa Kỳ vào những năm 1960. Mạng Cơ quan Chỉ đạo các Dự án Nghiên cứu Tiên tiến (ARPANET) đã đi vào hoạt động năm 1971 và thiết lập nhiều khái niệm của internet. Có lẽ khái niệm mang tính sống còn nhất chính là chuyển mạch gói (packet switching), tức là kỹ thuật tách dữ liệu ra thành các gói (packets) nhỏ hơn và đi kèm với thông tin được gọi là phần tiêu đề (header).
Ví dụ, giả sử Máy tính A đang chứa một tệp văn bản bự cỡ 30.000 byte. Máy tính B được kết nối với Máy tính A theo một cách nào đó. Nó gửi một yêu cầu đòi cái tệp văn bản này từ Máy tính A thông qua các tín hiệu truyền qua đường truyền. Máy tính A sẽ đáp trả bằng cách trước tiên chia nhỏ cái tệp văn bản này thành 20 phần, mỗi phần 1500 byte. Mỗi gói tin này chứa một phần tiêu đề xác định nguồn gửi (Máy tính A), đích đến (Máy tính B), tên của tệp, và các con số định danh gói tin—ví dụ, phần 7 trên tổng số 20. Máy tính B sẽ báo nhận từng gói tin và sau đó ráp chúng lại thành tệp hoàn chỉnh. Nếu thấy thiếu một gói cụ thể nào đó (có thể bị rơi rớt trong lúc truyền tải), nó sẽ gọi xin lại một bản sao của cái gói đó.
Phần tiêu đề cũng có thể chứa một tổng kiểm tra (checksum), là một con số được tính toán theo một cách chuẩn hóa từ tất cả các byte của tệp. Bất cứ khi nào Máy tính B nhận được một gói tin, nó thực hiện phép tính này và đối chiếu kết quả với cái tổng kiểm tra đó. Nếu không khớp, nó buộc phải cho rằng gói đó đã bị hư trong quá trình vận chuyển. Nó sẽ lập tức yêu cầu gửi lại một bản sao khác của gói tin.
Chuyển mạch gói có hàng tá lợi thế so với việc bê nguyên tệp bự chà bá gửi đi. Thứ nhất, đường truyền giữa hai máy tính sẽ luôn sẵn sàng để "share" cho máy tính khác trao đổi các gói tin của riêng chúng. Không có một máy tính nào có thể "bao rạp" hệ thống chỉ bằng một lệnh yêu cầu tải tệp siêu to. Thứ hai, nếu phát hiện lỗi trong một gói tin, ta chỉ cần phải gửi lại riêng mỗi gói đó thay vì phải bê nguyên cả tệp gửi lại từ đầu.
Xuyên suốt cuốn sách này, bạn đã thấy cách thông tin kỹ thuật số được truyền tải qua các sợi dây. Dòng điện chạy qua dây là số 1 nhị phân, và không có dòng điện là số 0. Nhưng dây dẫn trong các mạch điện mà cuốn sách này vẽ ra khá là ngắn. Truyền thông tin kỹ thuật số qua các chặng đường dài hơn cần những chiến thuật khác.
Điện thoại cố định (landlines) đã trở thành phương tiện truyền thông kỹ thuật số đường dài thuở sơ khai nhất, đơn giản vì chúng đã có sẵn và cực kỳ tiện lợi. Nhưng hệ thống điện thoại vốn được sinh ra để cho con người nói và nghe. Về mặt kỹ thuật, hệ thống điện thoại truyền tải dạng sóng âm thanh trong dải từ 300 Hz đến 3400 Hz, được coi là đủ dùng cho giọng nói con người.
Một cách tiếp cận đơn giản để phù phép các số 0 và 1 nhị phân thành dạng sóng âm thanh là thông qua một quá trình tên là điều chế (modulation), tức là làm biến đổi một tín hiệu âm thanh tương tự (analog) theo một cách nào đó để nó mã hóa thông tin kỹ thuật số.
Ví dụ, một thiết bị điều chế đời đầu là Bell 103, do AT&T sản xuất từ năm 1962, nhưng nó có một sức ảnh hưởng dai dẳng kéo dài đến tận những năm 1990. Thiết bị này có thể hoạt động ở chế độ full duplex, nghĩa là nó có thể vừa gửi vừa nhận thông tin cùng một lúc. Ở một đầu đường dây điện thoại là trạm gọi (originating station), và đầu kia là trạm nghe (answering station). Hai trạm này í ới với nhau ở tốc độ 300 bit mỗi giây.
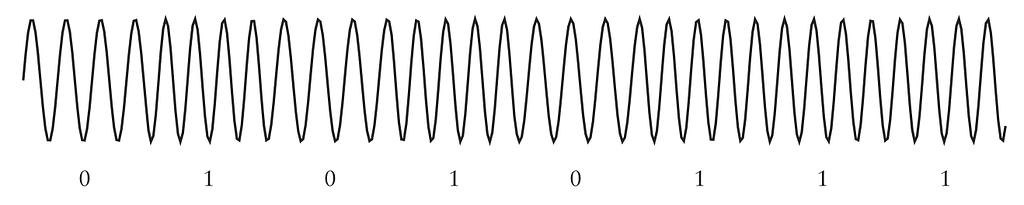
Bell 103 dùng một kỹ thuật gọi là điều chế khóa dịch tần (frequency-shift keying - FSK) để mã hóa số 0 và 1 vào trong tín hiệu âm thanh. Trạm gọi mã hóa số 0 nhị phân thành một âm thanh có tần số 1.070 Hz, và số 1 nhị phân thành 1.270 Hz. Đây là mã ASCII 8-bit cho chữ W được mã hóa thành hai tần số này:
Tần số của ASCII 8 bit cho W
Có thể hơi khó nhìn ra trong sơ đồ này, nhưng khoảng trống giữa các chu kỳ cho bit 0 nhỉnh hơn một chút so với bit 1 vì tần số thấp hơn. Trạm nghe cũng hoạt động y chang ngoại trừ việc nó dùng các tần số 2.025 Hz và 2.225 Hz. Thường thì một bit chẵn lẻ (parity bit) được kẹp thêm vào như một hình thức kiểm lỗi đơn giản.
Thiết bị làm nhiệm vụ điều chế âm thanh này để mã hóa dữ liệu nhị phân cũng có khả năng giải điều chế (demodulating) một luồng âm thanh truyền tới và biến nó ngược trở lại thành các số 0 và 1. Những thiết bị này vì thế được gọi là modulator-demodulator, hay modem.
Modem Bell 103 có thể truyền dữ liệu với tốc độ 300 bit mỗi giây. Nó cũng được gọi là một thiết bị 300 baud, một đơn vị đo lường được đặt theo tên của Émile Baudot, người mà bạn đã diện kiến ở Chương 13. Tốc độ baud là tốc độ truyền ký hiệu (symbol rate), và thỉnh thoảng nó bằng với tốc độ bit trên giây, thỉnh thoảng lại không. Ví dụ, giả sử bạn chế ra một sơ đồ FSK dùng bốn tần số khác nhau để biểu diễn các chuỗi bit 00, 01, 10, và 11. Nếu dạng sóng biểu diễn những âm thanh này thay đổi 1000 lần mỗi giây thì được phân loại là 1000 baud, nhưng nó truyền được tới 2000 bit mỗi giây.
Modem 300-baud khi kết nối hai máy tính thường tạo ra âm thanh rè rè chói tai. Âm thanh này hay được dùng trong các chương trình truyền hình và phim ảnh để khơi lại ký ức thời máy tính gia đình những năm 1980 và 1990.
Dần dà, các modem hoạt động trên đường dây điện thoại kỹ thuật số đã đạt tới tốc độ 56 kilobit mỗi giây. Chúng được gọi là modem 56K, và vẫn còn bám trụ ở vài khu vực. Tốc độ kết nối nhanh hơn có thể đạt được với đường dây thuê bao kỹ thuật số (DSL), cáp đồng trục, và vệ tinh. Bọn này chuyên chở các dạng sóng ở tần số vô tuyến, và những kỹ thuật điều chế tinh vi bậc thầy cho phép nhồi nhét lượng thông tin kỹ thuật số khổng lồ vào trong dạng sóng để đạt được tốc độ truyền kỹ thuật số nhanh hơn nhiều.
Một phương tiện liên lạc hoàn toàn khác được dùng cho hầu hết các tuyến cáp internet liên lục địa cũng như các đường truyền nối giữa các khu vực ven biển. Chôn vùi dưới đáy biển là muôn vàn tuyến cáp quang (fiber-optic cables). Đây là những sợi cáp làm từ sợi thủy tinh hoặc nhựa mỏng manh mang theo những chùm ánh sáng hồng ngoại. Hiển nhiên là ánh sáng bình thường không thể uốn cong, nhưng ánh sáng sẽ nảy bên trong bề mặt sợi quang nên sợi quang tuy bẻ cong nhưng vẫn xài tốt.
Vài trăm sợi quang thường được bện lại với nhau thành một sợi cáp, cho phép mỗi sợi gánh vác một tín hiệu đường truyền riêng biệt. Có những sợi quang bản thân nó có thể chở theo nhiều tín hiệu cùng lúc. Thông tin kỹ thuật số được mã hóa trong cáp quang bằng cách chớp nháy ánh sáng: Ánh sáng về cơ bản được tắt và bật cực nhanh, trong đó tắt là số 0 và bật là số 1. Đây chính là điều giúp giao tiếp tốc độ cao có thể xảy ra cho internet hiện đại.
Hình trạng mạng (Topology) cũng mang tính sống còn: Internet lẽ ra đã có thể được tạo ra bằng cách xây một siêu máy tính bự đùng ở đâu đó trên thế giới rồi kết nối mọi chiếc máy tính khác vào. Về vài khía cạnh, việc này sẽ làm cho internet đơn giản đi rất nhiều. Nhưng kế hoạch đơn giản này cũng lắm nhược điểm: Những người sống cách xa máy tính trung tâm sẽ phải chịu độ trễ cao hơn, và nếu nó mà sập nguồn thì sẽ kéo sập luôn toàn bộ internet của thế giới.
Thay vào đó, internet mang tính phi tập trung (decentralized), với vô số điểm dự phòng và không có một điểm yếu chí mạng nào. Đúng là vẫn tồn tại những chiếc máy tính siêu to khổng lồ lưu trữ hàng núi dữ liệu. Chúng được gọi là máy chủ (servers), trong khi những máy tính nhỏ hơn truy cập dữ liệu này đôi khi được gọi là máy khách (clients). Nhưng những máy tính khách mà chúng ta xài không kết nối trực tiếp với máy chủ. Thay vào đó, bạn chui vào internet thông qua một nhà cung cấp dịch vụ internet (ISP). Bạn chắc hẳn biết ISP của mình là ai vì hàng tháng bạn đều phải "nôn" tiền phí cho họ. Nếu bạn vào internet bằng điện thoại di động, thì nhà mạng viễn thông cũng chính là ISP của bạn.
Bên cạnh đủ thứ dây nhợ, cáp quang và sóng vô tuyến, mọi ngóc ngách trên internet đều được kết nối với nhau thông qua các bộ định tuyến (routers), chúng mang tên này là vì chuyên làm nhiệm vụ vạch ra một lộ trình (route) giữa máy khách và máy chủ. Bạn có thể đang có một bộ định tuyến ngay trong nhà mình tích hợp trong modem mà bạn dùng để lướt nét, hoặc tích hợp trong cục phát Wi-Fi. Mấy bộ định tuyến này có giắc cắm cho cáp Ethernet để có thể kết nối vật lý với máy tính và có thể với máy in.
Những bộ định tuyến đóng vai trò như các mắt xích của internet thì tinh vi hơn nhiều so với mấy bộ định tuyến ở nhà. Hầu hết chúng được kết nối với các bộ định tuyến khác, và truyền các gói tin đi, rồi những bộ định tuyến này lại nối với bộ định tuyến khác nữa, tạo thành một mạng lưới đan chéo phức tạp. Bộ định tuyến mang trong mình cả một CPU riêng vì chúng lưu trữ bảng định tuyến (routing tables) hoặc một chính sách định tuyến thuật toán chỉ ra lộ trình ngắn nhất để một gói tin tới đích.
Một mảnh ghép phần cứng phổ biến khác là bộ điều khiển giao diện mạng (network interface controller), hay NIC. Mỗi NIC đều được ban cho một định danh duy nhất vốn là phần cố định của phần cứng. Định danh này chính là địa chỉ điều khiển truy cập đa phương tiện, hay địa chỉ MAC (media access control). Một địa chỉ MAC được cấu thành từ tổng cộng 12 chữ số thập lục phân, thỉnh thoảng được nhóm lại thành sáu nhóm, mỗi nhóm hai chữ số.
Mọi thiết bị phần cứng kết nối với internet đều sở hữu một địa chỉ MAC của riêng mình. Máy tính để bàn và laptop thường có nhiều địa chỉ cho cổng kết nối Ethernet, Wi-Fi, và Bluetooth (thứ chuyên dùng để bắt sóng với các thiết bị quanh đó bằng sóng radio). Bạn hoàn toàn có thể lùng ra địa chỉ MAC này bằng cách vào phần Settings trên máy tính của mình. Modem và cục phát Wi-Fi của bạn cũng có địa chỉ MAC và chúng thường được in trên tem dán ở thiết bị. Điện thoại của bạn rất có thể cũng có địa chỉ MAC cho Wi-Fi và Bluetooth. Việc xài 12 chữ số thập lục phân cho địa chỉ MAC ngầm đảm bảo rằng trái đất này sẽ còn lâu mới cạn kiệt chúng. Sẽ có tận hơn 30.000 địa chỉ MAC cho mỗi người trên hành tinh này.
Mặc dù internet hỗ trợ hàng loạt các dịch vụ khác nhau, tỷ như email hay chia sẻ tệp, nhưng đa số dân tình tương tác với internet qua World Wide Web, một thứ gần như được phát minh phần lớn bởi nhà khoa học người Anh Tim Berners-Lee (sinh năm 1955) vào năm 1989. Khi tạo ra web, ông lấy luôn từ "hypertext", vốn dĩ đã được Ted Nelson tạo ra từ hồi Berners-Lee mới có 10 tuổi.
Định dạng tài liệu cơ bản nhất trên web được gọi là một trang (page) hay một trang web (webpage), bao gồm văn bản dùng Ngôn ngữ Đánh dấu Siêu văn bản (HTML). Bạn đã được thấy sơ sơ HTML ở chương trước. Các tài liệu HTML có chứa thẻ văn bản như <p> để chỉ một đoạn văn (paragraph), <h1> cho tiêu đề to nhất, và <img> cho một hình ảnh bitmap.
Một trong những thẻ HTML quan trọng nhất là <a>, viết tắt của anchor (mỏ neo). Thẻ mỏ neo này sẽ bao bọc một siêu liên kết (hyperlink), vốn dĩ hay xuất hiện dưới dạng một đoạn văn bản ngắn được định dạng khác biệt đi (thường là gạch chân) mà hễ click hay chạm vào là nó sẽ hiển thị một trang web khác. Đây chính là cách mà nhiều trang web được "xích" lại với nhau. Có khi các liên kết này có thể trỏ tới những nơi khác nhau trong một tài liệu dài—hao hao giống mục lục trong sách—và có khi liên kết lại có thể làm cầu nối dẫn tới các nguồn tham khảo hay thông tin bổ sung để nếu cứ kiên trì đi theo sẽ đào bới sâu hơn vào chủ đề nào đó.
Chỉ khoảng hai mươi năm tồn tại, web đã phình to một cách chóng mặt. Kể cả H. G. Wells hay Vannevar Bush cũng chẳng thể nào mường tượng nổi tiềm năng khổng lồ cho nghiên cứu trực tuyến, mua sắm, giải trí, hay tận hưởng các video mèo, và sự cám dỗ của việc nhảy vào combat các vấn đề chính trị với một đám người lạ hoắc lạ huơ. Thật ra, cuộc cách mạng máy tính ở thời kỳ tiền-internet giờ nhìn lại có vẻ như chỉ là một bức tranh dang dở. Internet đã vươn mình trở thành đỉnh cao và là sự hoàn kim của cuộc cách mạng máy tính, và mức độ thành công của cuộc cách mạng này phải được đem ra soi xét dựa trên sự tốt đẹp mà internet đã đem đến thế giới này. Thôi thì nhường chủ đề đó cho những bộ óc có khả năng tư duy cao siêu hơn tôi vậy.
Các trang trên web được chỉ định bằng một thứ gọi là Bộ Định vị Tài nguyên Đồng nhất, hay URL (Uniform Resource Locator). Một trong những trang trên website mà tôi dựng cho cuốn sách này có URL là
URL này bao gồm một tên miền (www.CodeHiddenLanguage.com), một thư mục (Chapter27), và một tệp HTML (index.html). URL khai mào bằng một thứ mang danh là giao thức (protocol). Tiền tố http tượng trưng cho Hypertext Transfer Protocol (Giao thức Truyền tải Siêu văn bản), trong khi https là bản biến tấu bảo mật hơn của HTTP. Những giao thức này mô tả cách mà một chương trình (như trình duyệt web) lấy các trang từ một trang web.
(Có điều hơi lú một tí là còn tồn tại một thứ gọi là Định danh Tài nguyên Đồng nhất, hay URI (Uniform Resource Identifier), mang định dạng cũng từa tựa URL nhưng có thể được xài như một định danh duy nhất thay vì gọi đến một trang web.)
Bất kỳ ứng dụng nào đang chạy trên một chiếc máy tính hiện đại đều có thể gọi tới hệ điều hành để khởi tạo một thứ gọi là yêu cầu HTTP (HTTP request). Chương trình này chẳng cần phải làm gì nhiều ngoài việc chỉ ra một URL dưới dạng một chuỗi văn bản, tỷ như "https://www.CodeHiddenLanguage.com". Một khoảng thời gian sau (hy vọng là không quá lâu), ứng dụng sẽ nhận được một phản hồi HTTP (HTTP response) trả lại cho ứng dụng trang web mà nó yêu cầu. Nếu yêu cầu thất bại, phản hồi là một mã lỗi. Ví dụ, nếu máy khách đòi lấy một tệp không tồn tại (chẳng hạn, https://www.CodeHiddenLanguage.com/FakePage.html), phản hồi sẽ là mã 404 quen thuộc, ngầm ý rằng không tìm thấy trang đó.
Những gì diễn ra giữa yêu cầu và phản hồi là màn giao tiếp khá rối rắm giữa máy khách (client) đưa ra yêu cầu và máy chủ (server) phản hồi.
URL của website chỉ là cái tên gọi thân thiện với con người để thay thế cho danh tính thực sự của nó, đó chính là địa chỉ Giao thức Internet (IP address)—ví dụ như 50.87.147.75. Đó là địa chỉ IP Phiên bản 4, là một số 32-bit. Địa chỉ IP Phiên bản 6 xài tới 128 bit. Để nhận được địa chỉ IP của website, trình duyệt web (hoặc ứng dụng khác) sẽ phải truy cập Hệ thống Tên miền (Domain Name System - DNS), nơi đóng vai trò như một quyển danh bạ lớn dùng để ánh xạ các URL sang các địa chỉ IP.
Địa chỉ IP của một website là cố định; máy tính khách cũng có một địa chỉ IP thường được ISP phát cho. Càng ngày, các đồ gia dụng trong nhà cũng bắt đầu có địa chỉ IP mà bạn có thể truy cập cục bộ bằng máy tính của mình. Những thiết bị gia dụng này là ví dụ của internet vạn vật, hay IOT.
Dù sao đi nữa, khi trình duyệt web của bạn đưa ra một yêu cầu HTTP cho một trang web, máy khách sẽ giao tiếp với máy chủ thông qua một bộ quy tắc được gọi chung là TCP/IP, nghĩa là Transmission Control Protocol (Giao thức Điều khiển Truyền vận) và Internet Protocol (Giao thức Internet). Đây chính là những giao thức làm nhiệm vụ chia một tệp ra thành nhiều gói tin và nhét thông tin tiêu đề vào trước dữ liệu. Các tiêu đề này mang theo địa chỉ IP của nguồn và đích, và vẫn nguyên si không đổi xuyên suốt hành trình gói tin băng qua các bộ định tuyến đang kết nối máy khách với máy chủ. Tiêu đề cũng bao gồm cả địa chỉ MAC của nguồn và đích. Chúng sẽ thay đổi khi gói tin từ bộ định tuyến này sang bộ định tuyến khác.
Hầu hết những bộ định tuyến này ôm trong mình một bảng định tuyến hoặc một quy tắc định tuyến chỉ ra lộ trình hiệu quả nhất để gói tin này đi từ máy khách đến máy chủ, và trả về của phản hồi từ máy chủ tới máy khách. Dẫn đường cho gói tin qua lại giữa các bộ định tuyến ắt hẳn là khía cạnh phức tạp nhất của internet.
Khi bạn lần đầu truy cập vào trang web CodeHiddenLanguage.com, có lẽ bạn đã gõ
CodeHiddenLanguage.com vào trình duyệt. Bạn không cần phải viết hoa có chủ đích tên miền như tôi đã làm đâu. Tên miền không phân biệt chữ hoa chữ thường.
Bản thân trình duyệt sẽ đắp thêm https:// vào trước tên miền đó khi đưa ra yêu cầu HTTP. Hãy chú ý là không hề có một tệp nào được chỉ định. Khi máy chủ nhận được yêu cầu trang CodeHiddenLanguage.com, thông tin đi kèm với trang đó bao gồm một danh sách chỉ định tệp nào sẽ được trả về. Với trang web này, tệp đứng trên đỉnh danh sách là default.html. Nó cũng như thể bạn đã gõ
CodeHiddenLanguage.com/default.html vào trình duyệt web vậy. Đó là trang chủ (home page) của trang web. Các trình duyệt web đều cho phép bạn kiểm tra trực tiếp tệp HTML thông qua tùy chọn như "View Page Source" (Xem Nguồn Trang).
Khi trình duyệt nhận được tệp default.html, nó sẽ bắt đầu phân tích cú pháp (parsing), một khái niệm mà tôi đã trình bày ở Chương 27. Quá trình này đòi hỏi phải quét qua văn bản tệp HTML từng ký tự một, xác định tất cả thẻ, và hiện lên trang web. Ở cấp độ CPU, việc phân tích cú pháp thường kéo theo các lệnh CMP theo sau bởi các lệnh nhảy có điều kiện. Công việc này thường được đẩy sang một nhóm phần mềm gọi là HTML engine, rất có thể được viết bằng C++. Trong lúc hiển thị trang web ra màn hình, trình duyệt web sẽ dùng tiện ích đồ họa của hệ điều hành.
Trong quá trình phân tích tệp default.html, trình duyệt web phát hiện ra rằng tệp này có thao khảo tới một tệp khác, mang tên style.css. Đây là tệp văn bản mang thông tin Bảng Định kiểu Xếp tầng (Cascading Style Sheets - CSS) nhằm mô tả chi tiết cách trang web này được định dạng. Trình duyệt web sẽ gọi thêm một yêu cầu HTTP nữa để mang tệp này về. Xuống phần dưới của trang default.html, trình duyệt web lại tìm thấy một tham chiếu tới tệp JPEG tên là Code2Cover.jpg. Đó là ảnh chụp bìa sách này. Lại thêm một yêu cầu HTTP nữa đi lấy tệp đó về.
Đi xuống dưới trang một xíu nữa là danh sách chương, kèm theo liên kết dẫn đến các trang khác trong website. Trình duyệt vẫn chưa tải mấy trang đó về vội mà chỉ hiện siêu liên kết (hyperlinks).
Khi bạn click vào liên kết cho Chương 6, chẳng hạn, trình duyệt sẽ gửi yêu cầu HTTP cho https://www.codehiddenlanguage.com/Chapter06. Một lần nữa, không có tệp nào được chỉ định, nhưng máy chủ sẽ lấy danh sách của nó ra dò. Tệp default.html xếp nhất, nhưng tệp đó lại không tồn tại trong thư mục Chapter06. Xếp nhì trong danh sách là index.html, và đó mới chính là tệp được trả về.
Trình duyệt sau đó phân tích trang. Trang này cũng có tệp style.css, nhưng trình duyệt web đã lưu bộ nhớ đệm (cached) của tệp này rồi, nghĩa là nó đã cất tệp ở đâu đó để lấy ra dùng sau này và mà chẳng cần tải lại nữa.
Trang index.html mang trong mình vài thẻ <iframe> trỏ tới các tệp HTML khác. Những tệp này cũng được tải xuống nốt. Chúng có phần <script> liệt kê vài tệp JavaScript. Những tệp JavaScript này cũng được tải về để mã JavaScript có thể được phân tích và thực thi.
Trước đây, mã JavaScript thường được thông dịch (interpreted) bởi trình duyệt web ngay trong lúc phân tích cú pháp. Thế nhưng ngày nay, các trình duyệt web đều có sẵn các "động cơ" JavaScript (JavaScript engines) chuyên làm nhiệm vụ biên dịch (compile) JavaScript—không phải dịch hết một lần đâu mà chỉ dịch khi nào cần tới thôi. Kỹ thuật này được gọi là biên dịch tức thời (just-in-time, hay JIT).
Dù cho trang web CodeHiddenLanguage.com phục vụ đồ họa tương tác cho máy tính, nhưng bản thân trang HTML lại tĩnh (static). Tuy nhiên, máy chủ hoàn toàn có khả năng cung cấp nội dung web động. Khi một máy chủ nhận một URL cụ thể, nó có thể làm bất cứ trò gì nó muốn với URL đó, và máy chủ có thể tạo ra các tệp HTML ngay khi yêu cầu (on the fly) và trả chúng cho máy khách.
Thi thoảng một tràng chuỗi truy vấn (query strings) sẽ được gắn vào URL. Chúng thường theo sau dấu chấm hỏi và cách nhau bởi dấu và (&). Máy chủ có thể phân tích và dịch được chúng. Máy chủ cũng hỗ trợ phong cách URL tên là REST (representational state transfer - chuyển giao trạng thái đại diện), chuyên gửi tệp dữ liệu từ máy chủ sang máy khách. Những món này được gọi là phía máy chủ (server-side) vì chúng liên quan tới chương trình chạy trên máy chủ, trong khi JavaScript lại là một ngôn ngữ lập trình phía máy khách (client-side). Các chương trình phía máy khách viết bằng JavaScript có thể tương tác với chương trình phía máy chủ trên chính máy chủ đó.
Lập trình web mang đến một kho tàng khổng lồ đến các lựa chọn, cứ nhìn sự muôn hình vạn trạng của các trang web là hiểu. Khi mà ngày càng nhiều quá trình xử lý và lưu trữ dữ liệu chuyển lên máy chủ, dần dà chúng được biết đến dưới cái tên gộp chung là đám mây (cloud). Khi mà ngày càng nhiều dữ liệu cá nhân của người dùng bị đưa lên đám mây, thì bản thân máy tính mà người ta hay xài để tạo ra hay truy xuất dữ liệu đó lại trở nên bớt quan trọng đi. Đám mây đã biến trải nghiệm máy tính thành lấy người dùng làm trung tâm (user-centric) thay vì lấy phần cứng làm trung tâm (hardware-centric).
Bạn có thắc mắc H. G. Wells hay Vannevar Bush sẽ nghĩ gì về internet không?
Cả Wells và Bush đều tin tưởng đầy lạc quan rằng việc nâng cấp khả năng tiếp cận tri thức và trí tuệ của thế giới là điều cốt lõi. Quả thực khó mà tranh cãi điều này. Nhưng một sự thật cũng khác là cho người ta đặc quyền đó cũng chẳng tự động đưa nền văn minh nhân loại bay vào kỷ nguyên vàng son. Người ta có vẻ dễ bị "ngợp" trước khối lượng thông tin khổng lồ bày ra trước mắt hơn là cảm giác có thể làm chủ nó.
Theo nghĩa internet đại diện cho một mẫu từ muôn hình vạn trạng các thể loại con người, tính cách, đức tin và sở thích, thì nó hẳn cũng là dạng Não Thế giới. Nhưng nó tuyệt đối không phải là "sự diễn giải chung về thực tại" mà Wells hằng ao ước. Gần như nổi tiếng ngang ngửa với tri thức đích thực là những biểu hiện sởn gai ốc của mớ khoa học dỏm và thuyết âm mưu nhảm nhí.
Tôi đồ rằng Wells hẳn sẽ mê mẩn ý tưởng về Google Books (books.google.com), vốn bắt nguồn từ việc scan và số hóa sách báo từ các thư viện khác nhau. Rất nhiều những cuốn sách trong số này—những cuốn không còn dính dáng tới bản quyền—đều có thể được lấy đọc trọn vẹn. Ngặt một nỗi, cha đẻ của Google Books có vẻ như đã quên mất thẻ thư mục (catalog cards), và thay vào đó ép người dùng phải dựa hoàn toàn vào công cụ tìm kiếm, mà bản thân chúng cũng lỗi bét nhè. Vấn đề cơ bản này thường khiến cho việc tìm một thứ cụ thể trên Google Books trở thành một trải nghiệm khá tệ.
Gần như trái với Google Books là JSTOR (www.jstor.org), viết tắt của Journal Storage, một kho chứa tạp chí học thuật nơi các bài báo đã được sắp xếp và lập danh mục một cách cẩn thận và hoàn hảo đến đáng tự hào. Ban đầu JSTOR là một trang giới hạn, nhưng sau một vụ lùm xùm đáng xấu hổ dính líu đến truy tố và tự tử đầy bi kịch của một lập trình viên ôm mộng miễn phí hoá nội dung của JSTOR, nó đã được nơi lỏng cho mọi người vào xem nhiều hơn.
Với những ai có thể đọc được ký âm của nhạc phương Tây truyền thống, thì Dự án Thư viện Bản nhạc Quốc tế (International Music Score Library Project - imslp.org) đối với bản nhạc cũng hệt như Google Books đối với sách vậy. IMSLP là một chiếc rương khổng lồ chứa các bản nhạc đã được số hóa không còn bị trói buộc bởi bản quyền, và may thay, chúng được phân loại và lập chỉ mục theo một cách cực kỳ dễ dùng.
Nếu bạn suy ngẫm về những ý tưởng của Vannevar Bush và Ted Nelson liên quan đến khả năng tự dệt nên một mạng lưới các tài liệu của riêng mình, thì có vẻ như vẫn còn khuyết mất một mảnh ghép nào đó. Mấy trang web như Google Books, JSTOR, và IMSLP có vẻ miễn nhiễm với kiểu liên kết tùy ý mà mấy ổng đã mơ mộng. Ứng dụng xử lý văn bản và bảng tính thời nay có cho phép lưu trữ link trỏ tới các nguồn thông tin, nhưng lại theo một cách chả mấy linh hoạt.
Trang web có thể gọi là suýt soát nhất với cái ý niệm Bách khoa Toàn thư Thế giới của Wells là Wikipedia (wikipedia.org). Định lý cốt lõi của Wikipedia—một cuốn bách khoa toàn thư cho phép người dùng chỉnh sửa—rất dễ dẫn đến một mớ hỗn mang và vô dụng. Nhưng dưới bàn tay chèo lái tận tụy và mẫn cán của Jimmy Wales (sinh năm 1966), nó lại trở thành trang web thiết yếu nhất trên internet.
Trong cuốn World Brain, H. G. Wells đã viết:
Một cuốn Bách khoa toàn thư muốn thu hút cả nhân loại thì không thể dung nạp những giáo điều thiển cận mà không đồng thời chấp nhận những lời phê bình mang tính sửa sai. Nó sẽ phải được các biên tập viên bảo vệ bằng sự ghen tuông tột độ trước cuộc xâm lăng không ngừng của những tuyên truyền hạn hẹp. Nó mang một sắc thái chung mà nhiều người sẽ gọi là hoài nghi. Huyền thoại, dù được tôn kính đến đâu cũng phải xem là huyền thoại chứ không phải như một sự diễn đạt mang tính biểu tượng của một chân lý cao cả hay sự lảng tránh nào đó tương tự. Nó phải phân biệt rạch ròi giữa những viễn cảnh, dự án, lý thuyết và thực tế vững chắc nền tảng. Nó nhất định phải chống lại mạnh mẽ những ảo tưởng vĩ cuồng của các quốc gia, và chống lại mọi giả định mang tính bè phái. Nó nhất định phải ủng hộ và không được thờ ơ với cộng đồng thế giới mà cuối cùng nó phải trở thành một phần thiết yếu trong đó. Nếu bạn gọi đó là định kiến, thì cuốn Bách khoa Toàn thư Thế giới này chắc chắn sẽ có định kiến. Nó sẽ có, và nó không thể không có, định kiến dành cho tổ chức, so sánh, xây dựng và sáng tạo. Về bản chất, nó là một dự án mang tính sáng tạo. Nó phải là yếu tố thống trị trong việc định hướng sự phát triển của một thế giới mới.
Đó quả là những mục tiêu đầy tham vọng, và thật đáng nể khi Wikipedia đã tiến rất gần đến đáp ứng những đòi hỏi này.
Tôi đồ rằng hầu hết chúng ta vẫn chưa thể đạt tới cảnh giới lạc quan như Wells khi tin rằng chỉ nguyên sự hiện diện của một kho tàng tri thức là có thể chỉ đường dẫn lối cho thế giới đi tới một tương lai sáng lạn hơn. Người ta hay rỉ tai nhau rằng cứ xây đi rồi khắc có người tới dùng, và cho dù chúng ta có muốn tin vào điều đó đến đâu đi nữa, thì cũng chẳng phải là một lời hứa chắc chắn. Bản tính con người hiếm khi theo đúng kỳ vọng.
Dù vậy, tất cả chúng ta đều phải nỗ lực làm những gì mình có thể.